It seems that our understanding is about the same, but there are one or two interesting points.
Allan, I've now read a large part of your website and I have got a more precise idea of your approach. I would not insist on the words "set cover" about it, because this is not the central aspect. The approach is not about transforming the whole Sudoku problem into an exact cover problem.
Yes, correct, the only relation to set-cover is the use of generic cover sets in a way similar to the dual cover process mentioned above, which must have its origins in early "fish" work.
It is about how to combine several set constraints and how to deal with the different "ranks" of these constraints. Most of the currently used rules are rank 0 or 1, for the mere reason that the higher the rank the more complex it becomes to find the patterns.
Right, mixed logic with different ranks is an advanced level and logic with uniform rank is the basic level. The theme is about the uniform properties (rank) over a region of sets, and how regions with different properties relate. Your right that most Sudoku methods are rank 0 or rank 1, but rank 2 logic is sometimes used along the way, such as AALSs.
Allan Barker wrote:
LAS produces static logic meaning there are no sequential steps or starting points, even for chains.
This is not specific to your approach. It seems that some people don't understand that a chain is a static pattern - they want to prove the chain rule every time they use it. They consider a chain as a chain of inferences instead of a static pattern. I've often written about this conceptual error.
Correct, I only point out that inference chains are not required. To me, patterns and inference chains are two ways of looking at the same thing, but of course quite different.
It doesn't seem you have a means of expressing and using sequentiality of patterns.
Not yet, since there was no need, but clearly something is needed for discussion purposes.
Conversely, being static doesn't mean that a chain has to be an unstructured pattern. A chain can be both static and sequentially ordered.
This is correct in this context, however, I was thinking of static vs. sequential more in a temporal sense. (more below)
Allan Barker wrote:
In this sense, the logic is pattern like or pictographic.
Now, the word "pictographic" seems very inappropariate - because of all the permutations that can be applied to a pattern, thus changing drastically its visual appearance without changing its fundamental logical nature. That's a point about your graphics. They are fabulous, but at some point they may hide the underlying logical structure. There's no difference between links along a row, a column or a number: that's what 3D symmetry really means. That's why I write an nrc-link simply as "-", whichever type it is (and others use other notations to the same effect).
Pictograms were meant to suggest features, I had learned to read Chinese at one point. What I really want to compare is how we recognize features and images in parallel whereas we process sequential logical thinking differently. Humans are very good at patterns and can easily see a chain no matter what the permutations are. Your point about simplified notation and nrc-links is also valid.
Allan Barker wrote:
The biggest distinction is between logic with uniform rank and logic that has regions of mixed rank. Rank is basically related to the number of missing constraints. Expanding on this a little gives the following kinds of logic.
1. Rank 0. Fish like logic, from X-wing to Steve's EM solution.
2. Rank 1. Chain like, Kraken fish, ALS wings and chains.
3. Rank 2, Kraken Blossoms? AALS units.
4. Mixed rank, overlap linksets (weak sets), nrct chains, finned fish.
5. Mixed rank, overlap sets (strong sets), broken wings, proving loops.
I agree that ranks 0, 1, 2 have a profound meaning - in part because they are tightly related to complexity. But "mixed rank" doens't seem to have a very precise meaning. When an nrc(z)(t) chain is built from left to right, it is not mixed rank, it is rank 1. This may be the indication that the notion of sequentiality of a pattern is missing in your approach.
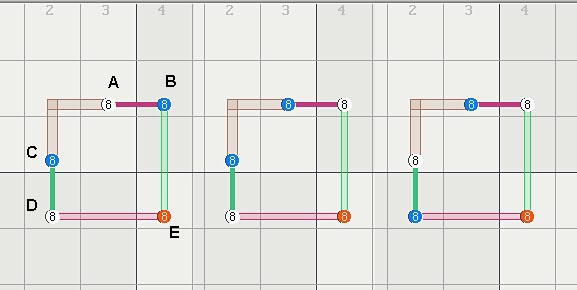
This goes to the heart of the matter. First, I should have given nrc(t)(z) chains more attention but I only listed nrc-t chains, nrc chains would be rank 1. However, a completed nrc-t chain, like the first of the 2 diagrams above, is mixed rank logic at least according to my system.
Now, go through the following situations. With no middle candidate in the top row, this is a rank 1, bi-value chain that eliminates the candidates in the lower right. Second, a middle candidate (X) in the top row not connected anywhere else requires one more linkset and the logic is 4 sets + 6 linksets = rank 2. This logic is uniform rank 2 everywhere and cannot eliminate anything.
Now connect X to some other candidate, Y. By necessity, this makes a triple point where 2 linksets overlap. According to the rules, the logic along the "set" branch is one rank higher. This branch points in the direction of set A, which is also rank 1 and thus eliminates the candidate at the intersection with set F. Eliminations can be caused by set B, which is also rank 1.
If X is wrongly connected to Y at an even node (second diagram above), then the triple-point points in the opposite direction and the logic is rank 1 through sets C and D. The end sets are both rank 2 and cannot make eliminations. Thus, this is not an nrc-t chain.
Thus, this simple set of considerations correctly explains why odd-node linked chains are nrct like and why even-node linked chains are not. It also explains why only one end of the nrct chain causes eliminations, which end does, and even which sets can cause eliminations.
It also predicts (shazam!) that for the even-linked chains, that either end can cause eliminations if it overlaps any of the internal linksets between X and the triple point. This is not true for the nrc-t chains.[/i]
Allan Barker wrote:
Then there are categories that seem to make less difference to the set logic:
1. No. of dimensions, 0D, 1D, 2D, 3D.
2. No. of candidates per set.
3. Branching. (related to no. of candidates per set)
But they make a great difference in terms of complexity of finding the patterns.
OK, good point, I think I would withdraw any real distinction between the first and second list, other than a personal preference on how to catagorize things.
I am not so knowledgeable about complexity, except I seem to make lots of it, or so I am told. However, I think the following two statements are both true. 1. Increasing the number of spatial dimensions allows additional kinds of logic that lead to more complexity. 2. A 3D bi-value (continuous nice) loop has the same complexity as a similar 2D loop.
What would be interesting now is an example of how you solve a puzzle using these rules. It is not yet very clear.
This is also a missing piece on the website. I am preparing something.