denis_berthier wrote:You should consider that we're now all waiting for a complete example. What's the output of your solver ?
I now have some time for a more detailed explanation as I see that any brief statement creates more confusion.
I will discuss a medium complex example first and then add some lengthy in another post. A braid example you gave in another post seem to be a good starting point before showing anything more complex.
As basic elimations (singles,pairs,box-line and some triples) are implemented directly, the first example has no steps derived from planes. But of course triples can be reduced from planes if you want to do that.
This is the puzzle:
- Code: Select all
98.7.....7.6...8...54......6..8..3......9..2......4..1.3.6..7......5..9......1..4 # 7658;GP;H1521
and this is the braid elimination justifying 5r9c8 false:
denis_berthier wrote:... one has the following S2-braid[14]:
S2-braid[14]: b9n3{r9c8 r8c9} - b9n6{r8c9 r789c7} - b9n8{r8c9 r7c789} - {n8r7c5 NP: b8{r7c5 r8c4}{n2 n4}} - r7c6{n2 n9} - r9c4{n9 n3} - {n3r5c4 HP: b5{r5c6 r6c5}{n3 n6}} - b5n7{r5c6 r4c456} - r4c8{n7 n4} - r5c7{n4 n5} - r4c9{n5 n9} - r6c7{n9 .} ==> r9c8 <> 5
with NP = Naked Pairs, HP = Hidden Pairs
The output of my solver for the same candidate elimination (cleaned from most of the junk) reads:
- Code: Select all
SUDOKU 98.7.....7.6...8...54......6..8..3......9..2......4..1.3.6..7......5..9......1..4
...
START P2_1 @ 5r9c8 IX=229 ##### +A
APPLY P2_1: S_5r9c8 E={518,528,548,568,578,579,591,593,597,398,698,898}
APPLY P2_1: S_3r8c9 B1=[3b9] T={319,329,339,384,386,289,689,889} C={389} D={398}
APPLY P2_1: T_N6C7B9 B1=[6b9] T={617,637,657,667} C={687,697} D={689,698}
APPLY P2_1: T_N8R7B9 B1=[8b9] T={871,873,875,876} C={878,879} D={889,898}
APPLY P2_1: S2_B6X68_N68B6 B2=[6b6|8b6] T={559,759,768} C={659,859,668,868} D={657,667}
APPLY P2_1: S2_B8X24_N24B8 B2=[r7c5|r8c4] T={276,286,294,295} C={275,475,284,484} D={875,384}
APPLY P2_1: S2_B8X68_N78B8 B2=[7b8|8b8] T={395} C={786,886,795,895} D={875,876}
APPLY P2_1: T_N7R4B6 B1=[7b6] T={742,743,745,746} C={748,749} D={759,768}
APPLY P2_1: S_9r7c6 B1=[r7c6] T={926,936,973,994} C={976} D={276,876}
APPLY P2_1: S_3r9c4 B1=[3b8] T={324,334,354,364} C={394} D={384,386,395}
APPLY P2_1: S2_B5X68_N67B5 B2=[6b5|7b5] T={356,265,365} C={656,756,665,765} D={745,746}
EMPTY P2_1: CONTRA B1=[3b5] D={354,356,364,365}
REDUCTION
REDUCE: S_5r9c8 B0 T={398,698,898} C={598} D={}
REDUCE: S_3r8c9 B1=[3b9] T={384,386,689,889} C={389} D={398}
REDUCE: T_N6C7B9 B1=[6b9] T={657,667} C={687,697} D={689,698}
REDUCE: T_N8R7B9 B1=[8b9] T={875,876} C={878,879} D={889,898}
REDUCE: S2_B6X68_N68B6 B2=[6b6|8b6] T={759,768} C={659,859,668,868} D={657,667}
REDUCE: S2_B8X68_N78B8 B2=[7b8|8b8] T={395} C={786,886,795,895} D={875,876}
REDUCE: T_N7R4B6 B1=[7b6] T={745,746} C={748,749} D={759,768}
REDUCE: S_3r9c4 B1=[3b8] T={354,364} C={394} D={384,386,395}
REDUCE: S2_B5X68_N67B5 B2=[6b5|7b5] T={356,365} C={656,756,665,765} D={745,746}
REDUCE: CONTRA B1=[3b5] T={} C={354,356,364,365} D={354,356,364,365}
RESULT: B12=[3b5|3b8|3b9|6b5|6b6|6b9|7b5|7b6|7b8|8b6|8b8|8b9]
Syntactical explanations:
nrc with n,r,c numbers 1..9 denotes number/row/column coordinates of candidates
nXm denotes lines, where n is number, X is r,c or b for row/column/box, and m is the line index
rXcY denotes cell lines, where X is row index, Y column index
There are two blocks of steps. The first block contains the raw contradiction sequence and the second the reduced elimination.
Each step has (mostly)
a name for better reading. ( S_ for singles, T_ for BI, S2_ for pairs ) You can ignore the details.
a list of base lines BX=[lines], X = number of base lines of the step
a list of target candidates T={,,,}
a list of core candidates C={,,,}
a list of dependencies D={,,,}
There is little to explain about the first block. After assuming 5r9c8 = true you apply basic eliminations until you find a contradiction. I also use the term
level-one elimination for the steps and
direct elimination for the result applied to the puzzle. Another interpretation is T&E(1) with basic eliminations. You can also say that it proves a puzzle with an extra given at 5r9c8 has no solution. The sequence of steps until contradiction is not unique and depends on the choice and order of applied level-one eliminations. The question of "right" can only be answered in relation to secondary solving goals (minimal size or complexity) otherwise one is as good as the other.
Although I defined eliminations generally with one target only, the steps usually show more than one. This is meant as more compact presentation of eliminations with the same dependencies. The dependency list of an elimination contains all candidates that are necessary to
enable the elimination. The dependencies are calculated from the base lines and the puzzle state at the beginning of the sequence. This is very near to the
almosting idea you presented elsewhere. The number of candidates that do "almosting" is not limited.
There is a major difference between level-one eliminations and direct eliminations. Direct ones have an absolute value by clearing the state of a candidate finally. Besides that they additionally reduce the dependency set of many potential eliminations. But level-one eliminations that trigger
no subsequent elimination are completely useless. The second block of steps contains the remaining level-one eliminations after all useless ones are deleted. This is done by backtracking the dependencies of the contradiction line down to the assumption. The value of eliminations is only visible in retrospect. The reduced sequence has less steps and less eliminations in some steps compared to the first block. The dependencies remain the same. The size of the result is 12, if you take the number of baselines as metric.
The path
assumption => contradiction means the same as the term
inverted logic used before and created questions. If someone does not like inverted logic, the paths are also readable backwards starting from the contradiction with exactly the same result.
Now some comments about the final result determined by all base lines occurring in reduced level-one eliminations.
None of the candidates can be omitted without breaking the logic, as it implies to omit the base line the candidate belongs to (see my initial post). So the result is minimal in the sense of the universal definition. Unfortunately the above reduction does not guarantee that the result fits to the last condition of the universal definition.
(4) there exists no subset of the defining candidate set that is a separate universal elimination pattern ( no cascading )This needs an additional check and is true in the example. The problem of compliance to (4) gets nasty with larger eliminations and is named "cannibal effect" also. An elimination should not delete targets that make up the defining structure.
More interesting aspects come from comparison with the S2-braid[14] alternative. My example should be a S2-braid[12] but I did not try to write it with your notation. Its not claim that I can find always eliminations with less baselines because I have a smarter strategy. But in this case its smaller and is a fine example where "simplest first" does not work as expected. If you prefer S+BI always before applying any pair you get exactly the S2-braid[14]. My example has three pairs instead of two but the lesser size is compensated by more links between candidates. My feeling is that by just counting the base lines some parts of complexity are ignored, but using alternative size function is another project.
This manually drawn graph of the example illustrates some more important things.
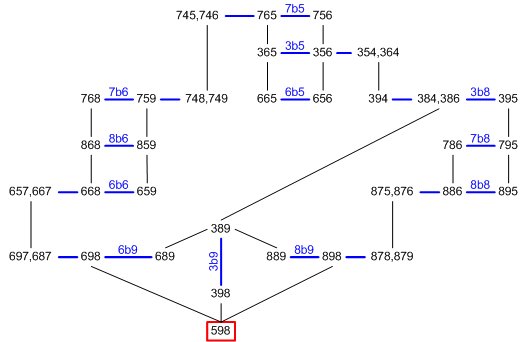
The graphics of xsudo are great for relatively small situations and improved my understanding. But for larger eliminations the mapping into the sudoku tableau gets confusing and I like more such abstract graphs. Would be great to create them by program.
Although you emphasized order many times, I can see little inherent chain-like order in this graph if order is meant as strict order. I am with you, if we exchange
order with
structure determined by the dependencies. But there are other inherent properties that are useful. Each link has a definite minimal distance from the target, where the distance is counted by links to go.
More important are candidate subsets I call
permutation rings. Such rings start from the target and return to the target following links that alternate between links inside baselines (blue color) and links between base lines (black color). Any base line should not used more than once. The number of links in such rings is always odd and each ring holds a partial permutation of candidate values. This is maybe another and better idea to define universal eliminations. It avoids also the permutation complications that
blue mentioned in the comment about base line uniqueness. But this needs more careful considerations about possible pitfalls.
The picture shows two 5-rings near the target and the maximal ring size is 23. There is no ring passing through all base lines.
I use these permutation rings when reducing eliminations from planes. A set of rings that cover all base lines makes an elimination. Working with planes has two advantages. First the target is already assured by the permutation check, so odd rings
must exist. Secondly planes or pairs of them are restricted areas small enough for a complete search. I did not implement this by now, but cut short the search if a size limit is reached.
I hope these explanations clear some of the fog. Next post tomorrow with an elimination example using plane sets and a full solution.