Hi, Tom!
Thank you for benchmarking my file!
At the first glance performance numbers are quite realistic. I need some time to ponder your results.
Serg
Tdoku: a speedy Sudoku solver
36 posts
• Page 2 of 3 • 1, 2, 3
Re: Tdoku: a speedy Sudoku solver
![]() by Serg » Fri Jun 28, 2019 9:12 am
by Serg » Fri Jun 28, 2019 9:12 am
- Serg
- 2018 Supporter
- Posts: 922
- Joined: 01 June 2010
- Location: Russia
Re: Tdoku: a speedy Sudoku solver
![]() by Serg » Fri Jun 28, 2019 9:15 am
by Serg » Fri Jun 28, 2019 9:15 am
Hi, Mathimagics!
Yes, it is my old benchmark dataset.
Serg
Mathimagics wrote:I have Serg's benchmark dataset, I assume it is the same as that which he sent me a few months back.
Yes, it is my old benchmark dataset.
Serg
- Serg
- 2018 Supporter
- Posts: 922
- Joined: 01 June 2010
- Location: Russia
Re: Tdoku: a speedy Sudoku solver
![]() by dobrichev » Fri Jun 28, 2019 5:42 pm
by dobrichev » Fri Jun 28, 2019 5:42 pm
Mathimagics wrote:My results are:
...
Clearly we have some anomalies here!
Hi, Mathimagics,
I got these results:
- Code: Select all
|38puz2123548 | puzzles/sec| usec/puzzle| %no_guess| guesses/puzzle|
|--------------------------------------|------------:| -----------:| ----------:| --------------:|
|tdoku_dpll_triad_simd | 146,185.9 | 6.8 | 0.1% | 3.92 |
|fsss2 | 228,022.7 | 4.4 | 0.0% | 5.49 |
|../data/serg.txt | puzzles/sec| usec/puzzle| %no_guess| guesses/puzzle|
|--------------------------------------|------------:| -----------:| ----------:| --------------:|
|tdoku_dpll_triad_simd | 228,896.7 | 4.4 | 0.0% | 7.13 |
|fsss2 | 330,324.1 | 3.0 | 0.0% | 7.76 |
m
where serg.txt is the file from Serg's url, and 38puz2123548 is a set of 38-givens minimal puzzles, a superset of 38's here.
I used Tom's test procedure and code before his latest changes. fsss2 was compiled with locked candidates disabled.
As you see, guesses/puzzle for tdoku_dpll_triad_simd in my test are consistent with Tom's test.
Also guesses/puzzle for fsss2 are "reasonable" but inconsistent with both your and Tom's test.
The puzzles/sec for fsss2 are inconsistent too.
So 2 questions to you
- Are you enabled locked candidates in fsss2 (as Tom did and I didn't)?
- Are you solving scrambled puzzles or original files? Tom is scrambling the puzzles and I used his test code.
- dobrichev
- 2016 Supporter
- Posts: 1891
- Joined: 24 May 2010
Re: Tdoku: a speedy Sudoku solver
![]() by Mathimagics » Fri Jun 28, 2019 6:18 pm
by Mathimagics » Fri Jun 28, 2019 6:18 pm
Hi Mladen,
I don't believe I have ever enabled "Locked Candidates" when building fsss2, or any of my variations …
And I didn't use any of Tom's benchmark stuff, just compiled his solver function which I then plugged into an existing program to perform Serg's benchmark test. Then I just pasted the results into that table which I posted using Tom's layout.
Definitely no puzzle was scrambled, so that would explain the differences in guesses/puzzle, I guess!
Cheers
MM
I don't believe I have ever enabled "Locked Candidates" when building fsss2, or any of my variations …
And I didn't use any of Tom's benchmark stuff, just compiled his solver function which I then plugged into an existing program to perform Serg's benchmark test. Then I just pasted the results into that table which I posted using Tom's layout.
Definitely no puzzle was scrambled, so that would explain the differences in guesses/puzzle, I guess!
Cheers
MM
-
Mathimagics - 2017 Supporter
- Posts: 1926
- Joined: 27 May 2015
- Location: Canberra
Re: Tdoku: a speedy Sudoku solver
![]() by dobrichev » Fri Jun 28, 2019 6:44 pm
by dobrichev » Fri Jun 28, 2019 6:44 pm
Thank you.
It is the (lack of) scrambling that explains the differences.
fsss2 benefits from minlex representation, namely from the denser bottom of the puzzle. Serg's collection is denser at the end of the puzzle too.
Surely for his implementation it is the best choice, but likely when guessing bi-value cells the preferred band (on otherwise equal conditions) should be the one with least pencilmarks.
I do not remember this being discussed in this forum.
Maybe, one day, I will try it and measure the |benefits| and sign(benefits).
It is the (lack of) scrambling that explains the differences.
fsss2 benefits from minlex representation, namely from the denser bottom of the puzzle. Serg's collection is denser at the end of the puzzle too.
Tom in https://t-dillon.github.io/tdoku/#GettingVectorized wrote:When determining the next guess to make instead of finding the most constrained cell or box, it turns out to be best to find the band with the fewest possible configurations across all values, and then to branch on the value that has the fewest configurations in the band.
Surely for his implementation it is the best choice, but likely when guessing bi-value cells the preferred band (on otherwise equal conditions) should be the one with least pencilmarks.
I do not remember this being discussed in this forum.
Maybe, one day, I will try it and measure the |benefits| and sign(benefits).
- dobrichev
- 2016 Supporter
- Posts: 1891
- Joined: 24 May 2010
Re: Tdoku: a speedy Sudoku solver
![]() by champagne » Fri Jun 28, 2019 9:18 pm
by champagne » Fri Jun 28, 2019 9:18 pm
dobrichev wrote:but likely when guessing bi-value cells the preferred band (on otherwise equal conditions) should be the one with least pencilmarks.
After many tests, I came just to the opposite conclusion.
Take in priority the band with more candidates. The underlying strategy being { a guess killing more candidates has a good chance to be the best guess).
This is the change is the last version of JCZsolver.
And it is the strategy in use in my current brute force.
- champagne
- 2017 Supporter
- Posts: 7942
- Joined: 02 August 2007
- Location: France Brittany
Re: Tdoku: a speedy Sudoku solver
![]() by Serg » Fri Jun 28, 2019 10:20 pm
by Serg » Fri Jun 28, 2019 10:20 pm
Hi, Tom!
Your benchmark run with my puzzles showed equal performance for fsss2 and JCZSolve with gcc compiler. I got similar (equal) performance numbers for fsss2 and JCZSolve with my puzzles on my notebook (Intel Core2 Duo CPU T8300 @ 2.40GHz, 32-bit MS Windows 7 + 32-bit GCC (version 8.1.0 from MinGW-W64 team)). JCZSolve performance (compiled with alone GCC option "-O2") was 212158 puzzles/sec. Your performance number JCZSolve (GCC) was 284000 puzzles/sec, i.e. 1.34 faster than my result. It can be explained by 1.5 times higher CPU frequency and more modern CPU in your computer. So, I think your results concerning fsss2 and JCZSolve are consistent with mine.
You reported 1.21 times higher performance of tdoku_dpll_triad_simd compared to JCZSolve (373,831.6 puzzles/sec versus 308,694.3 puzzles/sec) on my benchmark data. Mathimagics and dobrichev cannot reproduce this result yet. Hope, an explanation will be found soon.
You reported higher performance of tdoku_dpll_triad_simd and JCZSolve compiled by clang C++ compiler compared to GCC (1.12 times faster for tdoku_dpll_triad_simd and 1.085 faster for JCZSolve). Not so high difference, but it's interesting.
In any way you got impressive results, congratulations!
Serg
Your benchmark run with my puzzles showed equal performance for fsss2 and JCZSolve with gcc compiler. I got similar (equal) performance numbers for fsss2 and JCZSolve with my puzzles on my notebook (Intel Core2 Duo CPU T8300 @ 2.40GHz, 32-bit MS Windows 7 + 32-bit GCC (version 8.1.0 from MinGW-W64 team)). JCZSolve performance (compiled with alone GCC option "-O2") was 212158 puzzles/sec. Your performance number JCZSolve (GCC) was 284000 puzzles/sec, i.e. 1.34 faster than my result. It can be explained by 1.5 times higher CPU frequency and more modern CPU in your computer. So, I think your results concerning fsss2 and JCZSolve are consistent with mine.
You reported 1.21 times higher performance of tdoku_dpll_triad_simd compared to JCZSolve (373,831.6 puzzles/sec versus 308,694.3 puzzles/sec) on my benchmark data. Mathimagics and dobrichev cannot reproduce this result yet. Hope, an explanation will be found soon.
You reported higher performance of tdoku_dpll_triad_simd and JCZSolve compiled by clang C++ compiler compared to GCC (1.12 times faster for tdoku_dpll_triad_simd and 1.085 faster for JCZSolve). Not so high difference, but it's interesting.
In any way you got impressive results, congratulations!
Serg
- Serg
- 2018 Supporter
- Posts: 922
- Joined: 01 June 2010
- Location: Russia
Re: Tdoku: a speedy Sudoku solver
![]() by tdillon » Sat Jun 29, 2019 4:59 am
by tdillon » Sat Jun 29, 2019 4:59 am
Hi all,
Here are a bunch of runs on Serg's dataset with various combinations of machine, compiler, and optimization level. Hopefully this will make it a little easier to find similar setups to facilitate comparison. The machines include two Ubuntu desktops, one with AVX2 and one without, as well as a Windows cloud VM and a Pixelbook. The compilers are clang-8 and various gcc. Most of the runs are -O3, but a few are -O2.
I've modified the fsss2 patch to take an option indicating whether or not to use locked candidates so that both versions can be compared in the same run. In these tables the "fsss2" results are for the default fsss2 configuration without locked candidates, while the "fsss2{0x1}" results are using locked candidates. Note that the numbers I've posted upthread as "fsss2" should be compared to "fsss2{0x1}" here since in previous runs I've been using locked candidates for better performance on harder puzzles.
I confess I am a little puzzled by the guesses/puzzle for fsss2. In all the prior runs I've done the fsss2 guesses/puzzle have been sensible for datasets where the puzzles have unique solutions. i.e., a slightly fewer guesses than JCZSolve with locked candidates enabled, a slightly more than JCZSolve without locked candidates. OTOH, in my runs the guesses/puzzle have looked too low for datasets with more than one solution per puzzle. This does suggest that there's a problem with the way I'm counting for fsss2. However, the results that Mathematics and Mladen have posted both have guesses/puzzle for fsss2 that look correct on this dataset. Is there some important difference in the version of fsss2 we're using? I'm just cloning the fsss2 github repository and applying the patch you see.
In Mladen's last result tdoku_dpll_triad_simd was running 69% as fast as fsss2 on this benchmark. If this was, as before, with GNU 6.4.0 -O3 -march=native on an i5-3470,
then it would be most comparable to the desktop2,build2 run below, which was 77% as fast as fsss2. So there's some difference, but it's in the ballpark.
Here are a bunch of runs on Serg's dataset with various combinations of machine, compiler, and optimization level. Hopefully this will make it a little easier to find similar setups to facilitate comparison. The machines include two Ubuntu desktops, one with AVX2 and one without, as well as a Windows cloud VM and a Pixelbook. The compilers are clang-8 and various gcc. Most of the runs are -O3, but a few are -O2.
I've modified the fsss2 patch to take an option indicating whether or not to use locked candidates so that both versions can be compared in the same run. In these tables the "fsss2" results are for the default fsss2 configuration without locked candidates, while the "fsss2{0x1}" results are using locked candidates. Note that the numbers I've posted upthread as "fsss2" should be compared to "fsss2{0x1}" here since in previous runs I've been using locked candidates for better performance on harder puzzles.
I confess I am a little puzzled by the guesses/puzzle for fsss2. In all the prior runs I've done the fsss2 guesses/puzzle have been sensible for datasets where the puzzles have unique solutions. i.e., a slightly fewer guesses than JCZSolve with locked candidates enabled, a slightly more than JCZSolve without locked candidates. OTOH, in my runs the guesses/puzzle have looked too low for datasets with more than one solution per puzzle. This does suggest that there's a problem with the way I'm counting for fsss2. However, the results that Mathematics and Mladen have posted both have guesses/puzzle for fsss2 that look correct on this dataset. Is there some important difference in the version of fsss2 we're using? I'm just cloning the fsss2 github repository and applying the patch you see.
In Mladen's last result tdoku_dpll_triad_simd was running 69% as fast as fsss2 on this benchmark. If this was, as before, with GNU 6.4.0 -O3 -march=native on an i5-3470,
then it would be most comparable to the desktop2,build2 run below, which was 77% as fast as fsss2. So there's some difference, but it's in the ballpark.
- Code: Select all
######################
# Desktop1
######################
$ grep -i model <(lscpu); grep -i flags <(lscpu) | tr ' ' '\n' | egrep "(sse|avx)" | xargs
Model: 158
Model name: Intel(R) Core(TM) i5-8600K CPU @ 3.60GHz
sse sse2 ssse3 sse4_1 sse4_2 avx avx2
## build 1:
$ build/run_benchmark -h
build info: GNU 6.5.0 -O3 -march=native
$ build/run_benchmark -s tdoku_dpll_triad_simd,jczsolve,fsss2,fsss2:1 data/puzzles6_serg_benchmark
|data/puzzles6_serg_benchmark | puzzles/sec| usec/puzzle| %no_guess| guesses/puzzle|
|--------------------------------------|------------:| -----------:| ----------:| --------------:|
|tdoku_dpll_triad_simd | 317,339.9 | 3.2 | 0.0% | 7.13 |
|jczsolve | 278,821.3 | 3.6 | 0.0% | 7.09 |
|fsss2 | 362,665.7 | 2.8 | 0.0% | 1.44 |
|fsss2{0x1} | 278,274.6 | 3.6 | 0.0% | 1.41 |
## build 2:
$ build/run_benchmark -h
build info: Clang 8.0.1 -O3 -march=native
$ build/run_benchmark -s tdoku_dpll_triad_simd,jczsolve,fsss2,fsss2:1 data/puzzles6_serg_benchmark
|data/puzzles6_serg_benchmark | puzzles/sec| usec/puzzle| %no_guess| guesses/puzzle|
|--------------------------------------|------------:| -----------:| ----------:| --------------:|
|tdoku_dpll_triad_simd | 363,350.3 | 2.8 | 0.0% | 7.13 |
|jczsolve | 301,407.6 | 3.3 | 0.0% | 7.09 |
|fsss2 | 326,511.8 | 3.1 | 0.0% | 1.44 |
|fsss2{0x1} | 254,249.8 | 3.9 | 0.0% | 1.41 |
######################
# Desktop2
######################
$ grep -i model <(lscpu); grep -i flags <(lscpu) | tr ' ' '\n' | egrep "(sse|avx)" | xargs
Model: 62
Model name: Intel(R) Core(TM) i7-4930K CPU @ 3.40GHz
sse sse2 ssse3 sse4_1 sse4_2 avx
## build 1:
$ build/run_benchmark -h
build info: GNU 5.5.0 -O3 -march=native
$ build/run_benchmark -s tdoku_dpll_triad_simd,jczsolve,fsss2,fsss2:1 data/puzzles6_serg_benchmark
|data/puzzles6_serg_benchmark | puzzles/sec| usec/puzzle| %no_guess| guesses/puzzle|
|--------------------------------------|------------:| -----------:| ----------:| --------------:|
|tdoku_dpll_triad_simd | 220,922.6 | 4.5 | 0.0% | 7.13 |
|jczsolve | 210,224.4 | 4.8 | 0.0% | 7.09 |
|fsss2 | 286,110.7 | 3.5 | 0.0% | 1.44 |
|fsss2{0x1} | 222,263.6 | 4.5 | 0.0% | 1.41 |
## build 2:
$ build/run_benchmark -h
build info: GNU 6.5.0 -O3 -march=native
$ build/run_benchmark -s tdoku_dpll_triad_simd,jczsolve,fsss2,fsss2:1 data/puzzles6_serg_benchmark
|data/puzzles6_serg_benchmark | puzzles/sec| usec/puzzle| %no_guess| guesses/puzzle|
|--------------------------------------|------------:| -----------:| ----------:| --------------:|
|tdoku_dpll_triad_simd | 219,589.2 | 4.6 | 0.0% | 7.13 |
|jczsolve | 211,990.3 | 4.7 | 0.0% | 7.09 |
|fsss2 | 283,084.8 | 3.5 | 0.0% | 1.44 |
|fsss2{0x1} | 224,056.9 | 4.5 | 0.0% | 1.41 |
## build 3:
$ build/run_benchmark -h
build info: Clang 8.0.1 -O3 -march=native
$ build/run_benchmark -s tdoku_dpll_triad_simd,jczsolve,fsss2,fsss2:1 data/puzzles6_serg_benchmark
|data/puzzles6_serg_benchmark | puzzles/sec| usec/puzzle| %no_guess| guesses/puzzle|
|--------------------------------------|------------:| -----------:| ----------:| --------------:|
|tdoku_dpll_triad_simd | 237,551.6 | 4.2 | 0.0% | 7.13 |
|jczsolve | 220,150.0 | 4.5 | 0.0% | 7.09 |
|fsss2 | 269,831.4 | 3.7 | 0.0% | 1.44 |
|fsss2{0x1} | 208,989.4 | 4.8 | 0.0% | 1.41 |
## build 4:
$ build/run_benchmark -h
build info: GNU 6.5.0 -O2 -march=native
$ build/run_benchmark -s tdoku_dpll_triad_simd,jczsolve,fsss2,fsss2:1 data/puzzles6_serg_benchmark
|data/puzzles6_serg_benchmark | puzzles/sec| usec/puzzle| %no_guess| guesses/puzzle|
|--------------------------------------|------------:| -----------:| ----------:| --------------:|
|tdoku_dpll_triad_simd | 201,596.9 | 5.0 | 0.0% | 7.13 |
|jczsolve | 207,840.0 | 4.8 | 0.0% | 7.09 |
|fsss2 | 267,627.5 | 3.7 | 0.0% | 1.44 |
|fsss2{0x1} | 204,536.7 | 4.9 | 0.0% | 1.41 |
######################
# GCP n1-standard-1 (Haswell) windows-server-2016 + CygWin
######################
$ grep -i model /proc/cpuinfo; grep -i flags /proc/cpuinfo | tr ' ' '\n' | egrep "(sse|avx)" | xargs
model : 63
model name : Intel(R) Xeon(R) CPU @ 2.30GHz
sse sse2 ssse3 sse4_1 sse4_2 avx avx2
$ build/run_benchmark.exe -h
build info: GNU 7.4.0 -O3 -march=native
$ build/run_benchmark.exe -s tdoku_dpll_triad_simd,jczsolve,fsss2,fsss2:1 data/puzzles6_serg_benchmark
|data/puzzles6_serg_benchmark | puzzles/sec| usec/puzzle| %no_guess| guesses/puzzle|
|--------------------------------------|------------:| -----------:| ----------:| --------------:|
|tdoku_dpll_triad_simd | 167,451.0 | 6.0 | 0.0% | 7.13 |
|jczsolve | 157,077.9 | 6.4 | 0.0% | 7.09 |
|fsss2 | 205,386.9 | 4.9 | 0.0% | 2.87 |
|fsss2{0x1} | 159,964.2 | 6.3 | 0.0% | 2.83 |
$ build/run_benchmark.exe -h
build info: Clang 5.0.1 -O3 -march=native
$ build/run_benchmark.exe -s tdoku_dpll_triad_simd,jczsolve,fsss2,fsss2:1 data/puzzles6_serg_benchmark
|data/puzzles6_serg_benchmark | puzzles/sec| usec/puzzle| %no_guess| guesses/puzzle|
|--------------------------------------|------------:| -----------:| ----------:| --------------:|
|tdoku_dpll_triad_simd | 187,838.6 | 5.3 | 0.0% | 7.13 |
|jczsolve | 168,512.0 | 5.9 | 0.0% | 7.09 |
|fsss2 | 192,897.5 | 5.2 | 0.0% | 2.87 |
|fsss2{0x1} | 148,797.4 | 6.7 | 0.0% | 2.82 |
######################
# Pixelbook
######################
$ grep -i model <(lscpu); grep -i flags <(lscpu) | tr ' ' '\n' | egrep "(sse|avx)" | xargs
Model: 142
Model name: 06/8e
sse sse2 ssse3 sse4_1 sse4_2 avx avx2
## build 1:
$ build/run_benchmark -h
build info: GNU 6.3.0 -O3 -march=native
$ build/run_benchmark -s tdoku_dpll_triad_simd,jczsolve,fsss2,fsss2:1 data/puzzles6_serg_benchmark
|data/puzzles6_serg_benchmark | puzzles/sec| usec/puzzle| %no_guess| guesses/puzzle|
|--------------------------------------|------------:| -----------:| ----------:| --------------:|
|tdoku_dpll_triad_simd | 175,763.0 | 5.7 | 0.0% | 7.13 |
|jczsolve | 160,024.1 | 6.2 | 0.0% | 7.09 |
|fsss2 | 218,493.1 | 4.6 | 0.0% | 1.44 |
|fsss2{0x1} | 166,447.2 | 6.0 | 0.0% | 1.41 |
## build 2:
$ build/run_benchmark -h
build info: Clang 3.8.1 -O3 -march=native
$ build/run_benchmark -s tdoku_dpll_triad_simd,jczsolve,fsss2,fsss2:1 data/puzzles6_serg_benchmark
|data/puzzles6_serg_benchmark | puzzles/sec| usec/puzzle| %no_guess| guesses/puzzle|
|--------------------------------------|------------:| -----------:| ----------:| --------------:|
|tdoku_dpll_triad_simd | 190,984.8 | 5.2 | 0.0% | 7.13 |
|jczsolve | 170,079.8 | 5.9 | 0.0% | 7.09 |
|fsss2 | 190,961.1 | 5.2 | 0.0% | 1.44 |
|fsss2{0x1} | 144,091.1 | 6.9 | 0.0% | 1.41 |
## build 3:
$ build/run_benchmark -h
build info: GNU 6.3.0 -O2 -march=native
$ build/run_benchmark -s tdoku_dpll_triad_simd,jczsolve,fsss2,fsss2:1 data/puzzles6_serg_benchmark
|data/puzzles6_serg_benchmark | puzzles/sec| usec/puzzle| %no_guess| guesses/puzzle|
|--------------------------------------|------------:| -----------:| ----------:| --------------:|
|tdoku_dpll_triad_simd | 163,148.0 | 6.1 | 0.0% | 7.13 |
|jczsolve | 155,002.3 | 6.5 | 0.0% | 7.09 |
|fsss2 | 197,388.3 | 5.1 | 0.0% | 1.44 |
|fsss2{0x1} | 147,621.8 | 6.8 | 0.0% | 1.41 |
- tdillon
- Posts: 66
- Joined: 14 June 2019
Re: Tdoku: a speedy Sudoku solver
![]() by tdillon » Sat Jun 29, 2019 6:05 am
by tdillon » Sat Jun 29, 2019 6:05 am
dobrichev wrote:Surely for his implementation it is the best choice, but likely when guessing bi-value cells the preferred band (on otherwise equal conditions) should be the one with least pencilmarks.
champagne wrote:After many tests, I came just to the opposite conclusion.
Take in priority the band with more candidates. The underlying strategy being { a guess killing more candidates has a good chance to be the best guess).
While I described my branch heuristic in two parts (first the band with fewest overall configurations, then the value with fewest configurations in the band), the actual aim was simply to implement the conventional heuristic of branching on one of the most constrained variables (where the variables in question are 54 band:values taking 6 configurations each instead of the usual 81 cells taking 9 values each).
I would have preferred to pick directly among the band:values with the fewest remaining configurations (which I'm not guaranteed to find the way I do things now), and in this case it would have been interesting to study how to break ties; but this was a bit expensive to compute. The way I do it now is close enough and cheaper.
I did play with a couple of other heuristics, including counting conflicts to do something like VSIDS, and including some efforts at value ordering as opposed to variable ordering. Some of these did reduce backtracking, but none were worth the cost.
- tdillon
- Posts: 66
- Joined: 14 June 2019
Re: Tdoku: a speedy Sudoku solver
![]() by Serg » Mon Jul 01, 2019 8:21 pm
by Serg » Mon Jul 01, 2019 8:21 pm
Hi, Tom!
You collected large volume of benchmark data. Cool!
We can see that clang compiler provides similar performance comparing it with gcc compiler.
I should say that your solver is rather sensitive to C++ compliler in use. It optimized for clang compiler. So, one should install clang compiler obligatorily if he wants to use your solver.
dobrichev demonstrated "secret" parameter of his solver, boosting fsss2 performance 1.3 times. Very impressive!
But it all has little to do with me. My computer is too outdated. The most modern feature of its CPU - SSE4.1 instruction set, processing 128-bit registers. But AVX and AVX2 process 256-bit registers.
I propose you to participate some Sudoku Mathematics investigations at this forum. There are many interesting challenges in this area!
Serg
You collected large volume of benchmark data. Cool!
We can see that clang compiler provides similar performance comparing it with gcc compiler.
I should say that your solver is rather sensitive to C++ compliler in use. It optimized for clang compiler. So, one should install clang compiler obligatorily if he wants to use your solver.
dobrichev demonstrated "secret" parameter of his solver, boosting fsss2 performance 1.3 times. Very impressive!
But it all has little to do with me. My computer is too outdated. The most modern feature of its CPU - SSE4.1 instruction set, processing 128-bit registers. But AVX and AVX2 process 256-bit registers.
I propose you to participate some Sudoku Mathematics investigations at this forum. There are many interesting challenges in this area!
Serg
- Serg
- 2018 Supporter
- Posts: 922
- Joined: 01 June 2010
- Location: Russia
Re: Tdoku: a speedy Sudoku solver
![]() by Mathimagics » Tue Jul 02, 2019 12:10 am
by Mathimagics » Tue Jul 02, 2019 12:10 am
I can't compile Tom's solver on Windows 10 with clang.
I installed from binaries obtained at LLVM 8.0.0 Win64.
I have renamed the simd version of the solver as "tdSolver.cpp":
Searched LLVM directory and definitely no "crtdefs.h" is supplied. GCC has one, so let's try that:
Urrrgghh …..
I installed from binaries obtained at LLVM 8.0.0 Win64.
I have renamed the simd version of the solver as "tdSolver.cpp":
- Code: Select all
c:\tdSolver\tdoku-master\buildCL>clang -O2 -march=native -c tdSolver.cpp -o tdSolver.o
In file included from tdSolver.cpp:2:
In file included from ./simd_vectors.h:5:
In file included from C:\LLVM\lib\clang\8.0.0\include\immintrin.h:32:
In file included from C:\LLVM\lib\clang\8.0.0\include\xmmintrin.h:39:
In file included from C:\LLVM\lib\clang\8.0.0\include\mm_malloc.h:27:
c:\LLVM\include\stdlib.h:9:10: fatal error: 'crtdefs.h' file not found
#include <crtdefs.h>
^~~~~~~~~~~
1 error generated.
Searched LLVM directory and definitely no "crtdefs.h" is supplied. GCC has one, so let's try that:
- Code: Select all
c:\tdSolver\tdoku-master\buildCL>
clang -O2 -march=native -c tdSolver.cpp -o tdSolver.o -Ic:\MinGW\x86_64-w64-mingw32\include
In file included from tdSolver.cpp:2:
In file included from ./simd_vectors.h:5:
In file included from C:\LLVM\lib\clang\8.0.0\include\immintrin.h:28:
C:\LLVM\lib\clang\8.0.0\include\mmintrin.h:81:40: error: cannot initialize a parameter of type
'__attribute__((__vector_size__(2 * sizeof(int)))) int' (vector of 2 'int' values) with an rvalue of type '__v2si'
(aka 'int')
return __builtin_ia32_vec_ext_v2si((__v2si)__m, 0);
^~~~~~~~~~~
(… many errors of similar form follow …)
Urrrgghh …..
-
Mathimagics - 2017 Supporter
- Posts: 1926
- Joined: 27 May 2015
- Location: Canberra
Re: Tdoku: a speedy Sudoku solver
![]() by tdillon » Tue Jul 02, 2019 3:56 am
by tdillon » Tue Jul 02, 2019 3:56 am
Thanks Serg!
Yes, each solver has a preferred compiler (clang for tdoku and jczsolve; gcc for fsss2), and it's interesting that the difference in performance between the better and worse compiler for tdoku is around twice the difference for jczsolve and fsss2. Tdoku wasn't optimized for clang per se (I did most development and optimization using gcc and only discovered clang was faster at the end), but it's certainly true that clang produces materially better code for tdoku.
Tdoku ought to perform best if you have AVX2, but it also performs well with SSE4.1, and in my experience the difference hasn't been huge (in some cases - Threadripper - it's faster to compile without AVX2 support). Desktop2 is the relevant benchmark above. This was the machine I did most development on, and while it supports SSE4.2 and AVX, tdoku doesn't rely on these instruction sets. The instruction levels that matter are SSE2 (supported, but definitely slow), SSE4.1 (almost full performance), AVX2 (full performance). Also, when Ice Lake processors arrive with vector popcount instructions Tdoku supports them, so this should give another boost, though obviously I can't say how much right now.
Serg wrote:I should say that your solver is rather sensitive to C++ compiler in use. It optimized for clang compiler.
Yes, each solver has a preferred compiler (clang for tdoku and jczsolve; gcc for fsss2), and it's interesting that the difference in performance between the better and worse compiler for tdoku is around twice the difference for jczsolve and fsss2. Tdoku wasn't optimized for clang per se (I did most development and optimization using gcc and only discovered clang was faster at the end), but it's certainly true that clang produces materially better code for tdoku.
Serg wrote:My computer is too outdated. The most modern feature of its CPU - SSE4.1 instruction set, processing 128-bit registers. But AVX and AVX2 process 256-bit registers.
Tdoku ought to perform best if you have AVX2, but it also performs well with SSE4.1, and in my experience the difference hasn't been huge (in some cases - Threadripper - it's faster to compile without AVX2 support). Desktop2 is the relevant benchmark above. This was the machine I did most development on, and while it supports SSE4.2 and AVX, tdoku doesn't rely on these instruction sets. The instruction levels that matter are SSE2 (supported, but definitely slow), SSE4.1 (almost full performance), AVX2 (full performance). Also, when Ice Lake processors arrive with vector popcount instructions Tdoku supports them, so this should give another boost, though obviously I can't say how much right now.
- tdillon
- Posts: 66
- Joined: 14 June 2019
Re: Tdoku: a speedy Sudoku solver
![]() by dobrichev » Sat Jul 06, 2019 8:50 am
by dobrichev » Sat Jul 06, 2019 8:50 am
champagne wrote:a guess killing more candidates has a good chance to be the best guess
I tried this. On some really exotic puzzle batches the performance boost is 50 times!
For ordinary puzzles the preliminary implementation works ~30% slower.
- dobrichev
- 2016 Supporter
- Posts: 1891
- Joined: 24 May 2010
Re: Tdoku: a speedy Sudoku solver
![]() by champagne » Sat Jul 06, 2019 11:26 am
by champagne » Sat Jul 06, 2019 11:26 am
dobrichev wrote:champagne wrote:a guess killing more candidates has a good chance to be the best guess
I tried this. On some really exotic puzzle batches the performance boost is 50 times!
For ordinary puzzles the preliminary implementation works ~30% slower.
One problem is that you can not pay a lot to optimize the process. This is why I just selected the band with more pencil marks.
- champagne
- 2017 Supporter
- Posts: 7942
- Joined: 02 August 2007
- Location: France Brittany
Re: Tdoku: a speedy Sudoku solver
![]() by tdillon » Thu Jul 11, 2019 2:36 am
by tdillon » Thu Jul 11, 2019 2:36 am
Hi all,
Thanks to champagne for pointing me to SK_BFORCE2 to reflect the latest performance of solvers derived from JCZSolve.
I've re-run benchmarks including SK_BFORCE2, and also reflecting some recent optimizations for Tdoku (the most important being a speedup in puzzle initialization). The results are illustrated in the charts below, and you can find the full details here: https://github.com/t-dillon/tdoku/tree/master/benchmarks
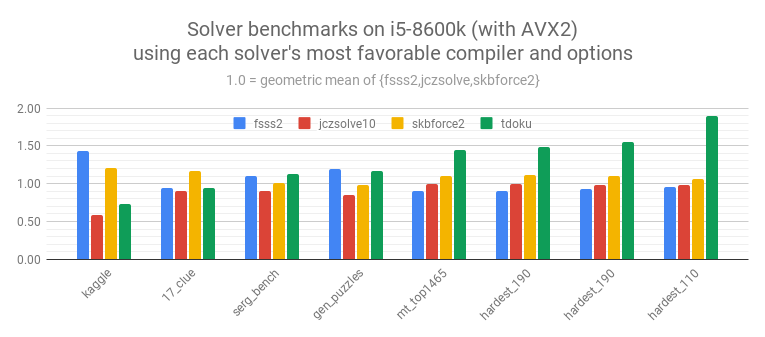
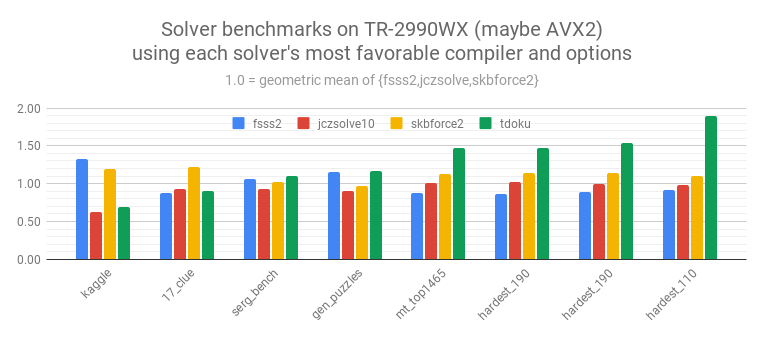
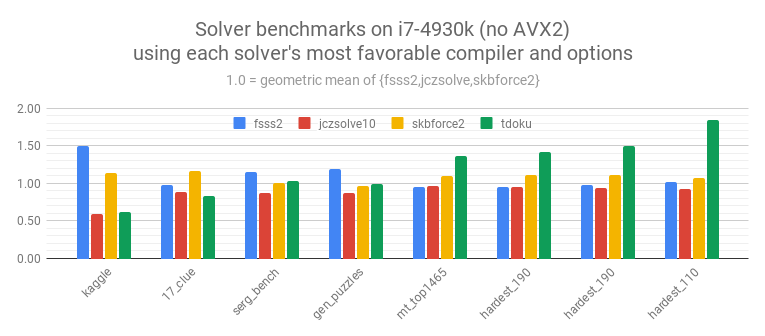
Benchmarks were run on 2 Intel machines and a Threadripper.
On each machine benchmarks were run with clang-8 and gcc-{6|7} with -O3 -march=native.
For FSSS2 benchmarks were run both with and without locked candidates.
For Threadripper benchmarks were also run with and without AVX2.
In the comparisons below the number used for each solver+dataset comes from the configuration that shows that solver in the most favorable light. For example, for FSSS2+mt_top1465 the best configuration is gcc with locked candidates, while for FSSS2+serg_benchmark it's gcc without locked candidates. As we've seen before clang is always faster than gcc for Tdoku. Interestingly, on Threadripper with clang Tdoku is faster *without* AVX2.
The results on the nearly-solved Kaggle dataset and 17-clue dataset are of scant interest I think, but they're included for completeness. Most folks here are probably interested in serg_benchmark and gen_puzzles, where Tdoku seems to be in line with the best solvers on modern hardware, but slower than FSSS2 on older machines. And, of course, my interest was with the datasets of hard puzzles, where Tdoku is fast.
Thanks to champagne for pointing me to SK_BFORCE2 to reflect the latest performance of solvers derived from JCZSolve.
I've re-run benchmarks including SK_BFORCE2, and also reflecting some recent optimizations for Tdoku (the most important being a speedup in puzzle initialization). The results are illustrated in the charts below, and you can find the full details here: https://github.com/t-dillon/tdoku/tree/master/benchmarks
Benchmarks were run on 2 Intel machines and a Threadripper.
On each machine benchmarks were run with clang-8 and gcc-{6|7} with -O3 -march=native.
For FSSS2 benchmarks were run both with and without locked candidates.
For Threadripper benchmarks were also run with and without AVX2.
In the comparisons below the number used for each solver+dataset comes from the configuration that shows that solver in the most favorable light. For example, for FSSS2+mt_top1465 the best configuration is gcc with locked candidates, while for FSSS2+serg_benchmark it's gcc without locked candidates. As we've seen before clang is always faster than gcc for Tdoku. Interestingly, on Threadripper with clang Tdoku is faster *without* AVX2.
The results on the nearly-solved Kaggle dataset and 17-clue dataset are of scant interest I think, but they're included for completeness. Most folks here are probably interested in serg_benchmark and gen_puzzles, where Tdoku seems to be in line with the best solvers on modern hardware, but slower than FSSS2 on older machines. And, of course, my interest was with the datasets of hard puzzles, where Tdoku is fast.
- tdillon
- Posts: 66
- Joined: 14 June 2019
36 posts
• Page 2 of 3 • 1, 2, 3
