Hello Obi-Wahn,
I don’t know if I have understood your definition of DDS, please correct me.
You look, how a set of N cells is distributed on a given set of N candidates. These candidates are locked in theses cells. The number of cells and the number of candidates are balanced.
1. The set of cells is called disjoint, if one type of number only occurs in one house (sector).
2. The set of cells is called almost disjoint, if there is at least one number, which occurs in more than one house. This number is called outlaw and can be eliminated outside the set of cells, otherwise we have only N-1 candidates for N cells.
3. The set of cells is called joint, if all types of numbers occur in one house.
The third case would cover all pairs, triples, quads, quins, …
I am sure that there are cases with more than one outlaw. Hardly to spot for a normal solver with pencil and paper.
Greetings
Gabriele
Distributed Disjoint Subsets
34 posts
• Page 2 of 3 • 1, 2, 3
![]() by StrmCkr » Wed Jul 30, 2008 6:37 pm
by StrmCkr » Wed Jul 30, 2008 6:37 pm
obi wans post.
they way i see any of these deductions is a tri value cell linked to 2/3 bivavlue digits in an aic chain that all conclude the same deduction.
i guess the subset count is based on the permations of the cell with 3 pms ???
like this.
R4C5(2) - (2=1)R4C7
|
R4C5(6) - (6=1)R7C5
|
R4C5(8) -(8=7)R6C4-(7=5)R8C4-(5=9)R8C7- (9=3)R8C8-(3=1)R9C8
or this last line can be written as this.
R4C5(8) - (8=7)R6C4 -(7=5)R8C5-(5=6)R7C4)-(6=1)R7C5
=> R7C7<>1
- Code: Select all
.---------------.---------------.---------------.
| 4 3 8 | 26 9 26 | 7 5 1 |
| 269 69 7 | 1 5 3 | 26 4 8 |
| 26 15 15 | 4 78 78 | 3 26 9 |
:---------------+---------------+---------------:
| 68 4 156 | 9 *268 568 |*12 7 3 |
| 679 15 1569| 3 267 567 | 8 12 4 |
| 78 2 3 |*78 4 1 | 69 69 5 |
:---------------+---------------+---------------:
| 3 7 4 | 56 *16 9 | 5-1 8 2 |
| 1 8 2 |*57 37 4 |*59 *39 6 |
| 5 69 69 | 28 13 28 | 4 *13 7 |
'---------------'---------------'---------------'
they way i see any of these deductions is a tri value cell linked to 2/3 bivavlue digits in an aic chain that all conclude the same deduction.
i guess the subset count is based on the permations of the cell with 3 pms ???
like this.
R4C5(2) - (2=1)R4C7
|
R4C5(6) - (6=1)R7C5
|
R4C5(8) -(8=7)R6C4-(7=5)R8C4-(5=9)R8C7- (9=3)R8C8-(3=1)R9C8
or this last line can be written as this.
R4C5(8) - (8=7)R6C4 -(7=5)R8C5-(5=6)R7C4)-(6=1)R7C5
=> R7C7<>1
Some do, some teach, the rest look it up.
stormdoku
stormdoku
-

StrmCkr - Posts: 1515
- Joined: 05 September 2006
![]() by Allan Barker » Fri Aug 01, 2008 12:09 pm
by Allan Barker » Fri Aug 01, 2008 12:09 pm
StrmCkr wrote
Ronk wrote re: Obi-Wahn's Six-Sector Disjoint Subset (previous page:)
I have seen other patterns with 3 aic legs and 4 legs is possible. Maybe another way to see all these deductions would be the following rule:
If all digits in N cells are contained in N + X houses, then all candidates contained in X + 1 houses can be eliminated.
X=0 for the 6-sector example and X=1 for the 3-leg aic (triopus??). I tried this on several examples here including the six-sector example from the previous page. It also works for subset exclusions and death blossoms. The rule will always be true but I'm not sure which methods it might fully cover or only partially cover.
The two thumbs below show diagrams for 1) Obiwan's 6 set example on the previous pageand 2) 3-leg (aic) cell.
...

I have a general discussion about set counting here. counting linksets
they way i see any of these deductions is a tri value cell linked to 2/3 bivavlue digits in an aic chain that all conclude the same deduction. i guess the subset count is based on the permations of the cell with 3 pms ???
Ronk wrote re: Obi-Wahn's Six-Sector Disjoint Subset (previous page:)
But I can't help but think there's also a connection to constraint sets. In this particular case, the almost-locked-sets in r1, c1 and c9 are "derived strong constraint sets" which are "exactly covered" by weak sets in r4, b1 and b3.
I have seen other patterns with 3 aic legs and 4 legs is possible. Maybe another way to see all these deductions would be the following rule:
If all digits in N cells are contained in N + X houses, then all candidates contained in X + 1 houses can be eliminated.
X=0 for the 6-sector example and X=1 for the 3-leg aic (triopus??). I tried this on several examples here including the six-sector example from the previous page. It also works for subset exclusions and death blossoms. The rule will always be true but I'm not sure which methods it might fully cover or only partially cover.
The two thumbs below show diagrams for 1) Obiwan's 6 set example on the previous pageand 2) 3-leg (aic) cell.
...

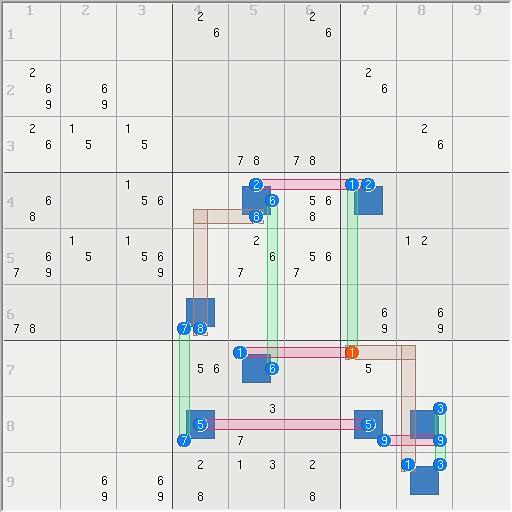
I have a general discussion about set counting here. counting linksets
- Allan Barker
- Posts: 266
- Joined: 20 February 2008
![]() by StrmCkr » Sat Aug 02, 2008 2:51 am
by StrmCkr » Sat Aug 02, 2008 2:51 am
triopus??). triplicated
there is also an easier set pattern to cover
there is 2 of them.
78 - 78 - 28 - 28 - 78 =>R5C6<>7
not going ot note the cells eactlyy they are all pairs in the above mentioned postes
or
26 - 28 - 78
| => R5C6 <>7
26 - 28 - 78
which leaves an xy wing... that removes the 1...
there is also an easier set pattern to cover
there is 2 of them.
78 - 78 - 28 - 28 - 78 =>R5C6<>7
not going ot note the cells eactlyy they are all pairs in the above mentioned postes
or
26 - 28 - 78
| => R5C6 <>7
26 - 28 - 78
which leaves an xy wing... that removes the 1...
Some do, some teach, the rest look it up.
stormdoku
stormdoku
-
StrmCkr - Posts: 1515
- Joined: 05 September 2006
![]() by PIsaacson » Sat Aug 02, 2008 1:30 pm
by PIsaacson » Sat Aug 02, 2008 1:30 pm
Obi-Wahn wrote:
I'm trying to add DSS to my own C++ solver, but I'm running into extremely long crunch times finding DSS > 6 cells/candidates. I'm using the same recursive algorithm that I use to locate normal subsets, except that instead of just scanning the 9 cells in a row/col/box, I'm scanning the entire grid. Here's a list of the number of comparisons and run times for locating DSSs for sizes 2 - 9:
This excludes the time to validate the DSS/ADSS, so I've tried various other algorithms, but I can't seem to find anything faster than brute force exhaustive scanning. Could you please shed some light on your algorithm?
Paul
I managed to extend my solver this way and it's still very fast. I can check hundreds of puzzles within just seconds. And it's probably still not optimal because I was glad to make it work at all.
I'm trying to add DSS to my own C++ solver, but I'm running into extremely long crunch times finding DSS > 6 cells/candidates. I'm using the same recursive algorithm that I use to locate normal subsets, except that instead of just scanning the 9 cells in a row/col/box, I'm scanning the entire grid. Here's a list of the number of comparisons and run times for locating DSSs for sizes 2 - 9:
- Code: Select all
Total iterations 2 levels = 3240 0.0059 msec
Total iterations 3 levels = 88560 0.2143 msec
Total iterations 4 levels = 1752300 2.8886 msec
Total iterations 5 levels = 27373896 37.0712 msec
Total iterations 6 levels = 351914112 633.0782 msec
Total iterations 7 levels = 3829130712 5888.2464 msec
Total iterations 8 levels = 35993384262 69380.4296 msec
Total iterations 9 levels = 296881218612 489414.6122 msec
This excludes the time to validate the DSS/ADSS, so I've tried various other algorithms, but I can't seem to find anything faster than brute force exhaustive scanning. Could you please shed some light on your algorithm?
Paul
- PIsaacson
- Posts: 249
- Joined: 02 July 2008
![]() by StrmCkr » Sun Aug 03, 2008 1:21 am
by StrmCkr » Sun Aug 03, 2008 1:21 am
how are you breaking your grid up?
by rows? columns?
a faster algorithim is by box, box box.
comparing n+2 digits to n+3 digit cells gernates the disjointed subsets.
and that would be box-box-box. for the 2 examples i list.
and same for obi wans.
by rows? columns?
a faster algorithim is by box, box box.
comparing n+2 digits to n+3 digit cells gernates the disjointed subsets.
and that would be box-box-box. for the 2 examples i list.
and same for obi wans.
Some do, some teach, the rest look it up.
stormdoku
stormdoku
-
StrmCkr - Posts: 1515
- Joined: 05 September 2006
![]() by PIsaacson » Sun Aug 03, 2008 8:48 pm
by PIsaacson » Sun Aug 03, 2008 8:48 pm
StrmCkr wrote:
Since I'm allowing the DSS to span any number of rows/cols/boxes, my algorithm doesn't limit itself to a particular house and it searches the entire grid cell by cell recursing to the level needed to match the desired size. That's why my comparison counts are in the billions by the time I hit DSS size 7. It's doing approximately ((( 81 * 80 / 2) * 79 / 2) ... * 73 / 2) tests to build the complete list of 9x9 DSSs. It takes about an hour for an exhaustive search, but it can exit much sooner if it happens to result in complete puzzle carnage. That's still much faster than my algorithm for complete subset counting which takes many hours to execute.
I'm not sure that I understand what you mean. Are you saying that I should locate all ALSs in each box and then complete them with outsiders? Or are you saying to locate all N cell N+2 candidates and then pair them with all N cell N+3 candidates? Or are you literally saying to pair each N+2 candidate cell with N+3 candidate cells? If so, then how do you ever satisfy the N cell N candidate condition? What am I missing here?
a faster algorithim is by box, box box
Since I'm allowing the DSS to span any number of rows/cols/boxes, my algorithm doesn't limit itself to a particular house and it searches the entire grid cell by cell recursing to the level needed to match the desired size. That's why my comparison counts are in the billions by the time I hit DSS size 7. It's doing approximately ((( 81 * 80 / 2) * 79 / 2) ... * 73 / 2) tests to build the complete list of 9x9 DSSs. It takes about an hour for an exhaustive search, but it can exit much sooner if it happens to result in complete puzzle carnage. That's still much faster than my algorithm for complete subset counting which takes many hours to execute.
I'm not sure that I understand what you mean. Are you saying that I should locate all ALSs in each box and then complete them with outsiders? Or are you saying to locate all N cell N+2 candidates and then pair them with all N cell N+3 candidates? Or are you literally saying to pair each N+2 candidate cell with N+3 candidate cells? If so, then how do you ever satisfy the N cell N candidate condition? What am I missing here?
- PIsaacson
- Posts: 249
- Joined: 02 July 2008
![]() by PIsaacson » Sun Aug 03, 2008 9:40 pm
by PIsaacson » Sun Aug 03, 2008 9:40 pm
Here's a trace log of my DSS algorithm processing the 1st example. By the time I get to the example's DSS, I've already found numerous other DSSs so there's no additional candidate eliminations, but it's there with another DSS formed by replacing the D element r5c2 <68> with r6c8 <46789>. You can see that it's really finding all possible DSSs (limited to size 6), so there's nothing fundamentally wrong with the algorithm, other than it's painfully slow for sizes 7-9. Also, you can see that it found a bunch of reductions after SSTS. Anyway here tis:
- Code: Select all
do_dss - starting with 28 total solved
19 3+ 256 |24579 24789 4579 |4568 45678 1678
8+ 7+ 25 |6+ 24 1+ |9+ 45 3+
19 4+ 56 |3579 3789 3579 |568 2+ 1678
--------- --------- --------- --------- --------- --------- --------- --------- ---------
2+ 15 1347 |8+ 379 6+ |345 4579 79
357 68 9+ |2347 2347 347 |1+ 45678 678
37 68 347 |1+ 5+ 3479 |23468 46789 26789
--------- --------- --------- --------- --------- --------- --------- --------- ---------
4+ 19 137 |37 367 2+ |68 689 5+
357 59 37 |347 3467 8+ |26 1+ 269
6+ 2+ 8+ |59 1+ 59 |7+ 3+ 4+
do_dss - disjoint subset <256> at r1c3 r2c3 r3c3
do_dss - disjoint subset <245> at r2c3 r2c5 r2c8
do_dss - disjoint subset <159> at r4c2 r7c2 r8c2
do_dss - disjoint subset <357> at r5c1 r6c1 r8c1
do_dss - disjoint subset <1689> at r1c1 r3c1 r5c2 r6c2
do_dss - disjoint subset <4568> at r1c7 r2c8 r3c7 r7c7
do_dss - reducing r1c8 <45678> by <4>
do_dss - reducing r1c8 <5678> by <5>
do_dss - reducing r6c7 <23468> by <6>
do_dss - reducing r8c7 <26> by <6>
do_dss - reducing r6c7 <2348> by <8>
do_dss - disjoint subset <1259> at r4c2 r7c2 r8c2 r8c7
do_dss - reducing r6c7 <234> by <2>
do_dss - reducing r8c9 <269> by <2>
do_dss - disjoint subset <1347> at r4c3 r6c3 r7c3 r8c3
do_dss - disjoint subset <2357> at r5c1 r6c1 r8c1 r8c7
do_dss - disjoint subset <5689> at r5c2 r6c2 r9c4 r9c6
do_dss - disjoint subset <3479> at r6c1 r6c3 r6c6 r6c7
do_dss - reducing r6c8 <46789> by <4>
do_dss - reducing r6c8 <6789> by <7>
do_dss - reducing r6c9 <26789> by <7>
do_dss - reducing r1c6 <4579> by <9>
do_dss - reducing r3c6 <3579> by <9>
do_dss - reducing r4c5 <379> by <9>
do_dss - reducing r6c8 <689> by <9>
do_dss - reducing r6c9 <2689> by <9>
do_dss - reducing r9c6 <59> by <9>
do_dss - disjoint subset <2347> at r6c1 r6c3 r6c7 r8c7
do_dss - reducing r6c6 <3479> by <3>
do_dss - reducing r6c6 <479> by <4>
do_dss - reducing r4c3 <1347> by <7>
do_dss - reducing r5c1 <357> by <7>
do_dss - reducing r6c6 <79> by <7>
do_dss - disjoint subset <3457> at r6c1 r6c3 r6c7 r9c6
do_dss - reducing r1c6 <457> by <5>
do_dss - reducing r3c6 <357> by <5>
do_dss - reducing r9c4 <59> by <5>
do_dss - disjoint subset <2689> at r6c2 r6c6 r6c8 r6c9
do_dss - disjoint subset <2689> at r6c2 r6c6 r6c8 r8c7
do_dss - reducing r6c9 <268> by <6>
do_dss - reducing r6c9 <28> by <8>
do_dss - disjoint subset <5689> at r6c2 r6c6 r6c8 r9c6
do_dss - disjoint subset <2689> at r6c2 r6c8 r6c9 r9c4
do_dss - reducing r1c4 <24579> by <9>
do_dss - reducing r3c4 <3579> by <9>
do_dss - disjoint subset <2568> at r6c2 r6c8 r6c9 r9c6
do_dss - disjoint subset <2689> at r6c2 r6c8 r8c7 r9c4
do_dss - disjoint subset <2568> at r6c2 r6c8 r8c7 r9c6
do_dss - disjoint subset <5689> at r6c2 r6c8 r9c4 r9c6
do_dss - disjoint subset <2689> at r6c9 r7c7 r7c8 r8c9
do_dss - disjoint subset <3467> at r7c4 r7c5 r8c4 r8c5
do_dss - disjoint subset <2689> at r7c7 r7c8 r8c7 r8c9
do_dss - disjoint subset <5689> at r7c7 r7c8 r8c9 r9c6
do_dss - disjoint subset <12569> at r1c1 r1c3 r2c3 r3c1 r3c3
do_dss - disjoint subset <13479> at r1c1 r1c6 r3c1 r3c6 r5c6
do_dss - disjoint subset <12459> at r1c1 r2c3 r2c5 r2c8 r3c1
do_dss - disjoint subset <13579> at r1c1 r3c1 r5c1 r6c1 r8c1
do_dss - disjoint subset <12689> at r1c1 r3c1 r5c2 r6c2 r6c9
do_dss - disjoint subset <12689> at r1c1 r3c1 r5c2 r6c2 r8c7
do_dss - disjoint subset <15689> at r1c1 r3c1 r5c2 r6c2 r9c6
do_dss - disjoint subset <13479> at r1c1 r3c1 r6c1 r6c3 r6c7
do_dss - disjoint subset <12689> at r1c1 r3c1 r6c2 r6c8 r6c9
do_dss - disjoint subset <12689> at r1c1 r3c1 r6c2 r6c8 r8c7
do_dss - disjoint subset <15689> at r1c1 r3c1 r6c2 r6c8 r9c6
do_dss - disjoint subset <23457> at r1c4 r1c6 r2c5 r3c4 r3c6
do_dss - reducing r1c5 <24789> by <2>
do_dss - reducing r3c5 <3789> by <3>
do_dss - reducing r1c5 <4789> by <4>
do_dss - reducing r1c5 <789> by <7>
do_dss - reducing r3c5 <789> by <7>
do_dss - disjoint subset <23457> at r1c4 r3c4 r5c4 r7c4 r8c4
do_dss - disjoint subset <34789> at r1c5 r1c6 r3c5 r3c6 r5c6
do_dss - disjoint subset <24589> at r1c5 r2c3 r2c5 r2c8 r3c5
do_dss - disjoint subset <35789> at r1c5 r3c5 r5c1 r6c1 r8c1
do_dss - disjoint subset <34789> at r1c5 r3c5 r6c1 r6c3 r6c7
do_dss - disjoint subset <34678> at r1c6 r3c6 r5c2 r5c6 r6c2
do_dss - disjoint subset <34678> at r1c6 r3c6 r5c6 r6c2 r6c8
do_dss - disjoint subset <23479> at r1c6 r3c6 r5c6 r6c6 r6c9
do_dss - disjoint subset <23479> at r1c6 r3c6 r5c6 r6c6 r8c7
do_dss - disjoint subset <34579> at r1c6 r3c6 r5c6 r6c6 r9c6
do_dss - disjoint subset <23479> at r1c6 r3c6 r5c6 r6c9 r9c4
do_dss - disjoint subset <23457> at r1c6 r3c6 r5c6 r6c9 r9c6
do_dss - disjoint subset <23479> at r1c6 r3c6 r5c6 r8c7 r9c4
do_dss - disjoint subset <23457> at r1c6 r3c6 r5c6 r8c7 r9c6
do_dss - disjoint subset <34579> at r1c6 r3c6 r5c6 r9c4 r9c6
do_dss - disjoint subset <45689> at r1c7 r2c8 r3c7 r6c6 r7c7
do_dss - disjoint subset <24568> at r1c7 r2c8 r3c7 r6c9 r7c7
do_dss - disjoint subset <24568> at r1c7 r2c8 r3c7 r7c7 r8c7
do_dss - disjoint subset <45689> at r1c7 r2c8 r3c7 r7c7 r9c4
do_dss - disjoint subset <34568> at r1c7 r3c7 r4c7 r6c7 r7c7
do_dss - disjoint subset <16789> at r1c9 r3c9 r4c9 r5c9 r8c9
do_dss - disjoint subset <24568> at r2c3 r2c5 r2c8 r5c2 r6c2
do_dss - disjoint subset <24568> at r2c3 r2c5 r2c8 r6c2 r6c8
do_dss - disjoint subset <23467> at r2c5 r4c5 r5c5 r7c5 r8c5
do_dss - disjoint subset <13457> at r4c2 r4c3 r5c1 r6c1 r6c3
do_dss - disjoint subset <15689> at r4c2 r5c2 r6c2 r7c2 r8c2
do_dss - disjoint subset <15689> at r4c2 r6c2 r6c8 r7c2 r8c2
do_dss - disjoint subset <13479> at r4c3 r6c3 r6c6 r7c3 r8c3
do_dss - disjoint subset <12347> at r4c3 r6c3 r6c9 r7c3 r8c3
do_dss - disjoint subset <12347> at r4c3 r6c3 r7c3 r8c3 r8c7
do_dss - disjoint subset <13479> at r4c3 r6c3 r7c3 r8c3 r9c4
do_dss - disjoint subset <13457> at r4c3 r6c3 r7c3 r8c3 r9c6
do_dss - disjoint subset <23479> at r4c5 r5c4 r5c5 r5c6 r6c6
do_dss - reducing r5c8 <45678> by <4>
do_dss - disjoint subset <23479> at r4c5 r5c4 r5c5 r5c6 r9c4
do_dss - disjoint subset <23457> at r4c5 r5c4 r5c5 r5c6 r9c6
do_dss - disjoint subset <35678> at r5c1 r5c2 r6c1 r6c2 r8c1
do_dss - disjoint subset <35678> at r5c1 r6c1 r6c2 r6c8 r8c1
do_dss - disjoint subset <23579> at r5c1 r6c1 r6c6 r6c9 r8c1
do_dss - disjoint subset <23579> at r5c1 r6c1 r6c6 r8c1 r8c7
do_dss - disjoint subset <23579> at r5c1 r6c1 r6c9 r8c1 r9c4
do_dss - disjoint subset <23579> at r5c1 r6c1 r8c1 r8c7 r9c4
do_dss - disjoint subset <34678> at r5c2 r6c1 r6c2 r6c3 r6c7
do_dss - disjoint subset <25689> at r5c2 r6c2 r6c6 r6c9 r9c6
do_dss - disjoint subset <25689> at r5c2 r6c2 r6c6 r8c7 r9c6
do_dss - disjoint subset <25689> at r5c2 r6c2 r6c9 r9c4 r9c6
do_dss - disjoint subset <25689> at r5c2 r6c2 r8c7 r9c4 r9c6
do_dss - disjoint subset <34678> at r6c1 r6c2 r6c3 r6c7 r6c8
do_dss - disjoint subset <23479> at r6c1 r6c3 r6c6 r6c7 r6c9
do_dss - disjoint subset <23479> at r6c1 r6c3 r6c6 r6c7 r8c7
do_dss - disjoint subset <34579> at r6c1 r6c3 r6c6 r6c7 r9c6
do_dss - disjoint subset <23479> at r6c1 r6c3 r6c7 r6c9 r9c4
do_dss - disjoint subset <23457> at r6c1 r6c3 r6c7 r6c9 r9c6
do_dss - disjoint subset <23479> at r6c1 r6c3 r6c7 r8c7 r9c4
do_dss - disjoint subset <23457> at r6c1 r6c3 r6c7 r8c7 r9c6
do_dss - disjoint subset <34579> at r6c1 r6c3 r6c7 r9c4 r9c6
do_dss - disjoint subset <25689> at r6c2 r6c6 r6c8 r6c9 r9c6
do_dss - disjoint subset <25689> at r6c2 r6c6 r6c8 r8c7 r9c6
do_dss - disjoint subset <25689> at r6c2 r6c8 r6c9 r9c4 r9c6
do_dss - disjoint subset <25689> at r6c2 r6c8 r8c7 r9c4 r9c6
do_dss - disjoint subset <34679> at r6c6 r7c4 r7c5 r8c4 r8c5
do_dss - disjoint subset <23467> at r6c9 r7c4 r7c5 r8c4 r8c5
do_dss - disjoint subset <25689> at r6c9 r7c7 r7c8 r8c9 r9c6
do_dss - disjoint subset <13579> at r7c2 r7c3 r8c1 r8c2 r8c3
do_dss - disjoint subset <23467> at r7c4 r7c5 r8c4 r8c5 r8c7
do_dss - disjoint subset <34679> at r7c4 r7c5 r8c4 r8c5 r9c4
do_dss - disjoint subset <34567> at r7c4 r7c5 r8c4 r8c5 r9c6
do_dss - disjoint subset <25689> at r7c7 r7c8 r8c7 r8c9 r9c6
do_dss - disjoint subset <123479> at r1c1 r1c6 r3c1 r3c6 r5c6 r6c9
do_dss - disjoint subset <123479> at r1c1 r1c6 r3c1 r3c6 r5c6 r8c7
do_dss - disjoint subset <134579> at r1c1 r1c6 r3c1 r3c6 r5c6 r9c6
do_dss - disjoint subset <145689> at r1c1 r1c7 r2c8 r3c1 r3c7 r7c7
do_dss - disjoint subset <123479> at r1c1 r3c1 r4c5 r5c4 r5c5 r5c6
do_dss - disjoint subset <123579> at r1c1 r3c1 r5c1 r6c1 r6c9 r8c1
do_dss - disjoint subset <123579> at r1c1 r3c1 r5c1 r6c1 r8c1 r8c7
do_dss - disjoint subset <125689> at r1c1 r3c1 r5c2 r6c2 r6c9 r9c6
do_dss - disjoint subset <125689> at r1c1 r3c1 r5c2 r6c2 r8c7 r9c6
do_dss - disjoint subset <123479> at r1c1 r3c1 r6c1 r6c3 r6c7 r6c9
do_dss - disjoint subset <123479> at r1c1 r3c1 r6c1 r6c3 r6c7 r8c7
do_dss - disjoint subset <134579> at r1c1 r3c1 r6c1 r6c3 r6c7 r9c6
do_dss - disjoint subset <125689> at r1c1 r3c1 r6c2 r6c8 r6c9 r9c6
do_dss - disjoint subset <125689> at r1c1 r3c1 r6c2 r6c8 r8c7 r9c6
do_dss - disjoint subset <134679> at r1c1 r3c1 r7c4 r7c5 r8c4 r8c5
do_dss - disjoint subset <234567> at r1c3 r1c6 r2c3 r3c3 r3c6 r5c6
do_dss - disjoint subset <234567> at r1c3 r2c3 r3c3 r6c1 r6c3 r6c7
do_dss - disjoint subset <234579> at r1c4 r1c6 r2c5 r3c4 r3c6 r6c6
do_dss - disjoint subset <234579> at r1c4 r1c6 r2c5 r3c4 r3c6 r9c4
do_dss - disjoint subset <234579> at r1c4 r3c4 r5c4 r6c6 r7c4 r8c4
do_dss - disjoint subset <234579> at r1c4 r3c4 r5c4 r7c4 r8c4 r9c4
do_dss - disjoint subset <234789> at r1c5 r1c6 r3c5 r3c6 r5c6 r6c9
do_dss - disjoint subset <234789> at r1c5 r1c6 r3c5 r3c6 r5c6 r8c7
do_dss - disjoint subset <345789> at r1c5 r1c6 r3c5 r3c6 r5c6 r9c6
do_dss - disjoint subset <134789> at r1c5 r3c5 r4c3 r6c3 r7c3 r8c3
do_dss - disjoint subset <234789> at r1c5 r3c5 r4c5 r5c4 r5c5 r5c6
do_dss - disjoint subset <235789> at r1c5 r3c5 r5c1 r6c1 r6c9 r8c1
do_dss - disjoint subset <235789> at r1c5 r3c5 r5c1 r6c1 r8c1 r8c7
do_dss - disjoint subset <234789> at r1c5 r3c5 r6c1 r6c3 r6c7 r6c9
do_dss - disjoint subset <234789> at r1c5 r3c5 r6c1 r6c3 r6c7 r8c7
do_dss - disjoint subset <345789> at r1c5 r3c5 r6c1 r6c3 r6c7 r9c6
do_dss - disjoint subset <346789> at r1c5 r3c5 r7c4 r7c5 r8c4 r8c5
do_dss - disjoint subset <134579> at r1c6 r3c6 r4c2 r5c6 r7c2 r8c2
do_dss - disjoint subset <346789> at r1c6 r3c6 r5c2 r5c6 r6c2 r6c6
do_dss - disjoint subset <234678> at r1c6 r3c6 r5c2 r5c6 r6c2 r6c9
do_dss - disjoint subset <234678> at r1c6 r3c6 r5c2 r5c6 r6c2 r8c7
do_dss - disjoint subset <346789> at r1c6 r3c6 r5c2 r5c6 r6c2 r9c4
do_dss - disjoint subset <345678> at r1c6 r3c6 r5c2 r5c6 r6c2 r9c6
do_dss - disjoint subset <346789> at r1c6 r3c6 r5c6 r6c2 r6c6 r6c8
do_dss - disjoint subset <234678> at r1c6 r3c6 r5c6 r6c2 r6c8 r6c9
do_dss - disjoint subset <234678> at r1c6 r3c6 r5c6 r6c2 r6c8 r8c7
do_dss - disjoint subset <346789> at r1c6 r3c6 r5c6 r6c2 r6c8 r9c4
do_dss - disjoint subset <345678> at r1c6 r3c6 r5c6 r6c2 r6c8 r9c6
do_dss - disjoint subset <234579> at r1c6 r3c6 r5c6 r6c6 r6c9 r9c6
do_dss - disjoint subset <234579> at r1c6 r3c6 r5c6 r6c6 r8c7 r9c6
do_dss - disjoint subset <234579> at r1c6 r3c6 r5c6 r6c9 r9c4 r9c6
do_dss - disjoint subset <346789> at r1c6 r3c6 r5c6 r7c7 r7c8 r8c9
do_dss - disjoint subset <234579> at r1c6 r3c6 r5c6 r8c7 r9c4 r9c6
do_dss - disjoint subset <145678> at r1c7 r1c8 r1c9 r2c8 r3c7 r3c9
do_dss - disjoint subset <245689> at r1c7 r2c8 r3c7 r6c6 r6c9 r7c7
do_dss - disjoint subset <245689> at r1c7 r2c8 r3c7 r6c6 r7c7 r8c7
do_dss - disjoint subset <245689> at r1c7 r2c8 r3c7 r6c9 r7c7 r9c4
do_dss - disjoint subset <245689> at r1c7 r2c8 r3c7 r7c7 r8c7 r9c4
do_dss - disjoint subset <345689> at r1c7 r3c7 r4c7 r6c6 r6c7 r7c7
do_dss - disjoint subset <234568> at r1c7 r3c7 r4c7 r6c7 r6c9 r7c7
do_dss - disjoint subset <234568> at r1c7 r3c7 r4c7 r6c7 r7c7 r8c7
do_dss - disjoint subset <345689> at r1c7 r3c7 r4c7 r6c7 r7c7 r9c4
do_dss - disjoint subset <456789> at r1c8 r2c8 r4c8 r5c8 r6c8 r7c8
do_dss - disjoint subset <126789> at r1c9 r3c9 r4c9 r5c9 r6c9 r8c9
do_dss - disjoint subset <126789> at r1c9 r3c9 r4c9 r5c9 r8c7 r8c9
do_dss - disjoint subset <156789> at r1c9 r3c9 r4c9 r5c9 r8c9 r9c6
do_dss - disjoint subset <245689> at r2c3 r2c5 r2c8 r5c2 r6c2 r6c6
do_dss - disjoint subset <245689> at r2c3 r2c5 r2c8 r5c2 r6c2 r9c4
do_dss - disjoint subset <245689> at r2c3 r2c5 r2c8 r6c2 r6c6 r6c8
do_dss - disjoint subset <245689> at r2c3 r2c5 r2c8 r6c2 r6c8 r9c4
do_dss - disjoint subset <245689> at r2c3 r2c5 r2c8 r7c7 r7c8 r8c9
do_dss - disjoint subset <234679> at r2c5 r4c5 r5c5 r6c6 r7c5 r8c5
do_dss - disjoint subset <234679> at r2c5 r4c5 r5c5 r7c5 r8c5 r9c4
do_dss - disjoint subset <234567> at r2c5 r4c5 r5c5 r7c5 r8c5 r9c6
do_dss - disjoint subset <456789> at r2c8 r4c8 r4c9 r5c2 r5c8 r5c9
do_dss - disjoint subset <456789> at r2c8 r4c8 r4c9 r5c8 r5c9 r6c8
do_dss - disjoint subset <134579> at r4c2 r4c3 r4c5 r4c7 r4c8 r4c9
do_dss - disjoint subset <134579> at r4c2 r4c3 r5c1 r6c1 r6c3 r6c6
do_dss - disjoint subset <123457> at r4c2 r4c3 r5c1 r6c1 r6c3 r6c9
do_dss - disjoint subset <123457> at r4c2 r4c3 r5c1 r6c1 r6c3 r8c7
do_dss - disjoint subset <134579> at r4c2 r4c3 r5c1 r6c1 r6c3 r9c4
do_dss - disjoint subset <125689> at r4c2 r5c2 r6c2 r6c9 r7c2 r8c2
do_dss - disjoint subset <125689> at r4c2 r5c2 r6c2 r7c2 r8c2 r8c7
do_dss - disjoint subset <134579> at r4c2 r6c1 r6c3 r6c7 r7c2 r8c2
do_dss - disjoint subset <125689> at r4c2 r6c2 r6c8 r6c9 r7c2 r8c2
do_dss - disjoint subset <125689> at r4c2 r6c2 r6c8 r7c2 r8c2 r8c7
do_dss - disjoint subset <134678> at r4c3 r5c2 r6c2 r6c3 r7c3 r8c3
do_dss - disjoint subset <134678> at r4c3 r6c2 r6c3 r6c8 r7c3 r8c3
do_dss - disjoint subset <123479> at r4c3 r6c3 r6c6 r6c9 r7c3 r8c3
do_dss - disjoint subset <123479> at r4c3 r6c3 r6c6 r7c3 r8c3 r8c7
do_dss - disjoint subset <134579> at r4c3 r6c3 r6c6 r7c3 r8c3 r9c6
do_dss - disjoint subset <123479> at r4c3 r6c3 r6c9 r7c3 r8c3 r9c4
do_dss - disjoint subset <123457> at r4c3 r6c3 r6c9 r7c3 r8c3 r9c6
do_dss - disjoint subset <123479> at r4c3 r6c3 r7c3 r8c3 r8c7 r9c4
do_dss - disjoint subset <123457> at r4c3 r6c3 r7c3 r8c3 r8c7 r9c6
do_dss - disjoint subset <134579> at r4c3 r6c3 r7c3 r8c3 r9c4 r9c6
do_dss - disjoint subset <234678> at r4c5 r5c2 r5c4 r5c5 r5c6 r6c2
do_dss - disjoint subset <234678> at r4c5 r5c4 r5c5 r5c6 r6c2 r6c8
do_dss - disjoint subset <234579> at r4c5 r5c4 r5c5 r5c6 r6c6 r9c6
do_dss - disjoint subset <234579> at r4c5 r5c4 r5c5 r5c6 r9c4 r9c6
do_dss - disjoint subset <356789> at r5c1 r5c2 r6c1 r6c2 r6c6 r8c1
do_dss - disjoint subset <235678> at r5c1 r5c2 r6c1 r6c2 r6c9 r8c1
do_dss - disjoint subset <235678> at r5c1 r5c2 r6c1 r6c2 r8c1 r8c7
do_dss - disjoint subset <356789> at r5c1 r5c2 r6c1 r6c2 r8c1 r9c4
do_dss - disjoint subset <356789> at r5c1 r6c1 r6c2 r6c6 r6c8 r8c1
do_dss - disjoint subset <235678> at r5c1 r6c1 r6c2 r6c8 r6c9 r8c1
do_dss - disjoint subset <235678> at r5c1 r6c1 r6c2 r6c8 r8c1 r8c7
do_dss - disjoint subset <356789> at r5c1 r6c1 r6c2 r6c8 r8c1 r9c4
do_dss - disjoint subset <356789> at r5c1 r6c1 r7c7 r7c8 r8c1 r8c9
do_dss - disjoint subset <346789> at r5c2 r6c1 r6c2 r6c3 r6c6 r6c7
do_dss - disjoint subset <234678> at r5c2 r6c1 r6c2 r6c3 r6c7 r6c9
do_dss - disjoint subset <234678> at r5c2 r6c1 r6c2 r6c3 r6c7 r8c7
do_dss - disjoint subset <346789> at r5c2 r6c1 r6c2 r6c3 r6c7 r9c4
do_dss - disjoint subset <345678> at r5c2 r6c1 r6c2 r6c3 r6c7 r9c6
do_dss - disjoint subset <346789> at r6c1 r6c2 r6c3 r6c6 r6c7 r6c8
do_dss - disjoint subset <234678> at r6c1 r6c2 r6c3 r6c7 r6c8 r6c9
do_dss - disjoint subset <234678> at r6c1 r6c2 r6c3 r6c7 r6c8 r8c7
do_dss - disjoint subset <346789> at r6c1 r6c2 r6c3 r6c7 r6c8 r9c4
do_dss - disjoint subset <345678> at r6c1 r6c2 r6c3 r6c7 r6c8 r9c6
do_dss - disjoint subset <234579> at r6c1 r6c3 r6c6 r6c7 r6c9 r9c6
do_dss - disjoint subset <234579> at r6c1 r6c3 r6c6 r6c7 r8c7 r9c6
do_dss - disjoint subset <234579> at r6c1 r6c3 r6c7 r6c9 r9c4 r9c6
do_dss - disjoint subset <346789> at r6c1 r6c3 r6c7 r7c7 r7c8 r8c9
do_dss - disjoint subset <234579> at r6c1 r6c3 r6c7 r8c7 r9c4 r9c6
do_dss - disjoint subset <234679> at r6c6 r6c9 r7c4 r7c5 r8c4 r8c5
do_dss - disjoint subset <234679> at r6c6 r7c4 r7c5 r8c4 r8c5 r8c7
do_dss - disjoint subset <345679> at r6c6 r7c4 r7c5 r8c4 r8c5 r9c6
do_dss - disjoint subset <123579> at r6c9 r7c2 r7c3 r8c1 r8c2 r8c3
do_dss - disjoint subset <234679> at r6c9 r7c4 r7c5 r8c4 r8c5 r9c4
do_dss - disjoint subset <234567> at r6c9 r7c4 r7c5 r8c4 r8c5 r9c6
do_dss - disjoint subset <136789> at r7c2 r7c3 r7c4 r7c5 r7c7 r7c8
do_dss - disjoint subset <123579> at r7c2 r7c3 r8c1 r8c2 r8c3 r8c7
do_dss - disjoint subset <234679> at r7c4 r7c5 r8c4 r8c5 r8c7 r9c4
do_dss - disjoint subset <234567> at r7c4 r7c5 r8c4 r8c5 r8c7 r9c6
do_dss - disjoint subset <345679> at r7c4 r7c5 r8c4 r8c5 r9c4 r9c6
do_dss - disjoint subset <345679> at r8c1 r8c2 r8c3 r8c4 r8c5 r8c9
19 3+ 256 |2457 89 47 |4568 678 1678
8+ 7+ 25 |6+ 24 1+ |9+ 45 3+
19 4+ 56 |357 89 37 |568 2+ 1678
--------- --------- --------- --------- --------- --------- --------- --------- ---------
2+ 15 134 |8+ 37 6+ |345 4579 79
35 68 9+ |2347 2347 347 |1+ 5678 678
37 68 347 |1+ 5+ 9 |34 68 2
--------- --------- --------- --------- --------- --------- --------- --------- ---------
4+ 19 137 |37 367 2+ |68 689 5+
357 59 37 |347 3467 8+ |2 1+ 69
6+ 2+ 8+ |9 1+ 5 |7+ 3+ 4+
do_dss - ending with 34 updates 28 total solved
- PIsaacson
- Posts: 249
- Joined: 02 July 2008
![]() by StrmCkr » Sun Aug 03, 2008 11:43 pm
by StrmCkr » Sun Aug 03, 2008 11:43 pm
I'm not sure that I understand what you mean. Are you saying that I should locate all ALSs in each box and then complete them with outsiders? Or are you saying to locate all N cell N+2 candidates and then pair them with all N cell N+3 candidates? Or are you literally saying to pair each N+2 candidate cell with N+3 candidate cells? If so, then how do you ever satisfy the N cell N candidate condition? What am I missing here?
basically its order of operands befor you run the search.
have blr, pairs,x wings als reduce the puzzle to its lowest pm position possible.
this counld leave many cells with 2 candidates and a few with three.
from here you can pair n+3 cells in conjunction with n+2 candidates on a row/ column in starting box a: and go from box to box. looking for connections. and perform the deductions based on limit of cell counting.
for example
26(box2) --------- 26 (box 2)
| |
| 78 (box2)
78(box5) |
x(box 5)
| |
28------------ 28(box8)
4 digits - 6 cells only 2 valid placemetns.
there for any reduction is limited by the "6" => either 7
or 7 is true and implyies the 6 is ture
implying x cannot be true. as x sees both truths.
i also read on here there is a faster algorth for how to store data off the grid based on boxs position
vers row/column.
Some do, some teach, the rest look it up.
stormdoku
stormdoku
-
StrmCkr - Posts: 1515
- Joined: 05 September 2006
![]() by PIsaacson » Mon Aug 04, 2008 7:39 am
by PIsaacson » Mon Aug 04, 2008 7:39 am
This might sound stupid, but can the DSS rules be applied to RN/CN/BN transposed spaces? My current recursive search takes less than 1 ms to do an exhaustive search of a normal RCN grid after SSTS for DSSs upto size 4x4. Since normal naked and hidden subsets are the inverse of each other, instead of burning cpu time looking for large DSSs in normal RCN space, I could easily search the RN/CN/BN spaces. Is this valid? Will it work? I'll modify my DSS test locator to search the alternate spaces tomorrow after I mull on this.
Cheers,
Paul
Cheers,
Paul
- PIsaacson
- Posts: 249
- Joined: 02 July 2008
![]() by StrmCkr » Mon Aug 04, 2008 7:58 pm
by StrmCkr » Mon Aug 04, 2008 7:58 pm
This might sound stupid, but can the DSS rules be applied to RN/CN/BN transposed spaces?
as individuals? should work to find hidden naked triples pairs singles. in each plane as its own interface.rn. cn. or bn.
then combinations of those to find larger ones? is that what your suggesting?
also a question. regarding this gird...
19 3+ 256 |24579 24789 4579 |4568 45678 1678
8+ 7+ 25 |6+ 24 1+ |9+ 45 3+
19 4+ 56 |3579 3789 3579 |568 2+ 1678
--------- --------- --------- --------- --------- --------- --------- --------- ---------
2+ 15 1347 |8+ 379 6+ |345 4579 79
357 68 9+ |2347 2347 347 |1+ 45678 678
37 68 347 |1+ 5+ 3479 |23468 46789 26789
--------- --------- --------- --------- --------- --------- --------- --------- ---------
4+ 19 137 |37 367 2+ |68 689 5+
357 59 37 |347 3467 8+ |26 1+ 269
6+ 2+ 8+ |59 1+ 59 |7+
there is many triples located on this grid that are not removing the locked portions is this done on purpose???
like the 256 on r123C3 => many reductions.... or are u trying to count this limitation of space as a subset count?
which technically it could be considered as one. but it is diffrent.
as individuals? should work to find hidden naked triples pairs singles. in each plane as its own interface.rn. cn. or bn.
then combinations of those to find larger ones? is that what your suggesting?
also a question. regarding this gird...
19 3+ 256 |24579 24789 4579 |4568 45678 1678
8+ 7+ 25 |6+ 24 1+ |9+ 45 3+
19 4+ 56 |3579 3789 3579 |568 2+ 1678
--------- --------- --------- --------- --------- --------- --------- --------- ---------
2+ 15 1347 |8+ 379 6+ |345 4579 79
357 68 9+ |2347 2347 347 |1+ 45678 678
37 68 347 |1+ 5+ 3479 |23468 46789 26789
--------- --------- --------- --------- --------- --------- --------- --------- ---------
4+ 19 137 |37 367 2+ |68 689 5+
357 59 37 |347 3467 8+ |26 1+ 269
6+ 2+ 8+ |59 1+ 59 |7+
there is many triples located on this grid that are not removing the locked portions is this done on purpose???
like the 256 on r123C3 => many reductions.... or are u trying to count this limitation of space as a subset count?
which technically it could be considered as one. but it is diffrent.
Some do, some teach, the rest look it up.
stormdoku
stormdoku
-
StrmCkr - Posts: 1515
- Joined: 05 September 2006
![]() by PIsaacson » Mon Aug 04, 2008 9:45 pm
by PIsaacson » Mon Aug 04, 2008 9:45 pm
Dear StrmCkr,
I want to thank you for continuing to look/answer my DSS questions. I'll try to answer your questions and give you the lastest info on my RN/CN/BN efforts:
My question is whether or not I can apply the standard hidden subset rule for eliminating candidates outside of the subset in each cell participating in the hidden subset. This is effectively the same as finding a naked subset of size (9 - sizeof (hidden)). I'm in the process of coding/debugging this. So far, I can quickly find ALL DSS size 2-4 very rapidly in RC space (less than 1ms) and that includes all normal naked subsets size 2-4. Perhaps that answers your question about the subset <256> for r123c3. It's actually the very first DSS that I have in my log
but there were no candidate eliminations detected. My test program only performs DSS analysis, so any missing naked/hidden singles or box/row/col coloring or other reductions are missing on purpose. I start with a grid from a known position (usually using Simple Sudoku SSTS) and then test to see how many reductions are possible and what size DSS subsets are most productive etc. I've added it to my full-blown solver, but placement in priority of algorithms is critical. Currently, I'm using it as a complete replacement for my normal subset processing, and while DSS is slow compared to standard SS, it finds many more reductions. My belief is that if I can get the hidden DSS to work correctly, I won't be plagued by the slow processing of scanning for DSSs > size 6. So regarding the combining of subsets to find larger ones... I've tried that, but it really isn't any faster than what I'm doing now. Problem with combinations is that you still have to check all smaller sized subsets for completions, so at size 7, you're still looking at all the size 6,5,4,3,2 sets. Combining was actually slower than my current recursion for some perverse reason -- maybe I didn't code it as efficiently, but the number of combine tests was still in the billions for size > 6.
As for subset counting... I've pretty much abandoned that for later study since it's so painfully slow.
I want to thank you for continuing to look/answer my DSS questions. I'll try to answer your questions and give you the lastest info on my RN/CN/BN efforts:
This might sound stupid, but can the DSS rules be applied to RN/CN/BN transposed spaces?
as individuals? should work to find hidden naked triples pairs singles. in each plane as its own interface.rn. cn. or bn.
then combinations of those to find larger ones? is that what your suggesting?
My question is whether or not I can apply the standard hidden subset rule for eliminating candidates outside of the subset in each cell participating in the hidden subset. This is effectively the same as finding a naked subset of size (9 - sizeof (hidden)). I'm in the process of coding/debugging this. So far, I can quickly find ALL DSS size 2-4 very rapidly in RC space (less than 1ms) and that includes all normal naked subsets size 2-4. Perhaps that answers your question about the subset <256> for r123c3. It's actually the very first DSS that I have in my log
- Code: Select all
do_dss - disjoint subset <256> at r1c3 r2c3 r3c3
but there were no candidate eliminations detected. My test program only performs DSS analysis, so any missing naked/hidden singles or box/row/col coloring or other reductions are missing on purpose. I start with a grid from a known position (usually using Simple Sudoku SSTS) and then test to see how many reductions are possible and what size DSS subsets are most productive etc. I've added it to my full-blown solver, but placement in priority of algorithms is critical. Currently, I'm using it as a complete replacement for my normal subset processing, and while DSS is slow compared to standard SS, it finds many more reductions. My belief is that if I can get the hidden DSS to work correctly, I won't be plagued by the slow processing of scanning for DSSs > size 6. So regarding the combining of subsets to find larger ones... I've tried that, but it really isn't any faster than what I'm doing now. Problem with combinations is that you still have to check all smaller sized subsets for completions, so at size 7, you're still looking at all the size 6,5,4,3,2 sets. Combining was actually slower than my current recursion for some perverse reason -- maybe I didn't code it as efficiently, but the number of combine tests was still in the billions for size > 6.
As for subset counting... I've pretty much abandoned that for later study since it's so painfully slow.
- PIsaacson
- Posts: 249
- Joined: 02 July 2008
![]() by StrmCkr » Tue Aug 05, 2008 1:51 am
by StrmCkr » Tue Aug 05, 2008 1:51 am
do_dss - disjoint subset <256> at r1c3 r2c3 r3c3
but there were no candidate eliminations detected
never mind... i now see that the grid was shifted alot...my bad.
actually... specking of inverse shouldnt it be.
a subset of 4 inversed should find size 5..
inverse subset of 3 should find size 6
inverse subset of 2 should be 7
Some do, some teach, the rest look it up.
stormdoku
stormdoku
-
StrmCkr - Posts: 1515
- Joined: 05 September 2006
![]() by PIsaacson » Tue Aug 05, 2008 2:05 pm
by PIsaacson » Tue Aug 05, 2008 2:05 pm
I've never quite figured out why this is so, but typically naked/hidden subsets are searched for sizes 2-4 only. That would seem to leave a "hole" in the 9 - size for the inverse, but I guess singletons and full decks (1 & 9) are respectively uninteresting. The better news is that I've got a much faster algorithm for finding all naked DSS sized 2-9, so I'm giving up on the hidden searching. I could transpose the space and execute the searches, but the reductions in RN/CN/BN space didn't result in valid boards after re-translating back to RC space. I've been looking at the traces and I'm kinda baffled because I thought that symmetry of translation allowed for equivalent operations in any space: pinning, restrictions, subsets, coloring, als, niceloops... should work in any space, shouldn't they???
- PIsaacson
- Posts: 249
- Joined: 02 July 2008
34 posts
• Page 2 of 3 • 1, 2, 3
